Webinar Recap: Introducing InfluxDB Clustered
By
Jessica Wachtel /
Developer, Product
Oct 09, 2023
Navigate to:
Time series data is foundational in almost all applications and services. Even if time series isn’t the focus, like in an IoT sensor data centered application, it appears in monitoring data as metrics, logs, and traces. Because of time series data’s unique characteristics, it’s best served in a time series database. InfluxDB is purpose-built to handle the high volume and velocity of time series ingestion, and perform real-time analytics, alerting, and anomaly detection at scale.
The webinar Introducing InfluxDB Clustered includes an in-depth demo of InfluxDB Clustered and a technical introduction of the self-managed, self-hosted instance of InfluxDB. Balaji Palani, Vice President of Product Marketing and Gunnar Aasen, Senior Product Manager dive into the details on why InfluxDB 3.0 handles high performance time series workloads with ease.
InfluxDB 3.0
InfluxDB is built on Apache Arrow an in-memory columnar format. Arrow provides real-time query responses on fresh or recently queried data. Arrow also provides low latency analytical query responses. In addition to the in-memory data store, InfluxDB persists data as Apache Parquet files on cloud object stores, such as Amazon S3. Parquet has high-ratio data compression, allowing customers to save more data in less space. Parquet’s superior compression leads to upwards of 10x more data stored at a reduced cost. In addition to the cost-saving benefits, customers have more of the data they need to perform historical trend analysis and train machine learning (ML) models.
Parquet is an open data standard enabling interoperability with ML tools and advanced analytics. Popular tools such as Grafana for visualization and Pandas DataFrame for analysis can work directly with Parquet files. Parquet’s zero copy data sharing means customers can read data into or access it from Snowflake, data lake, or ML platforms directly without copying any data.
InfluxDB 3.0 uses the DataFusion query engine which brings native SQL support to InfluxDB 3.0 in addition to InfluxQL Benefits of the DataFusion query engine include vectorized execution, optimized I/O pushdown strategies, optimized data partitioning, and state of the art parallelism techniques. DataFusion is performance-optimized for columnar analytics. DataFusion delivers fast results even when querying across longer time ranges.
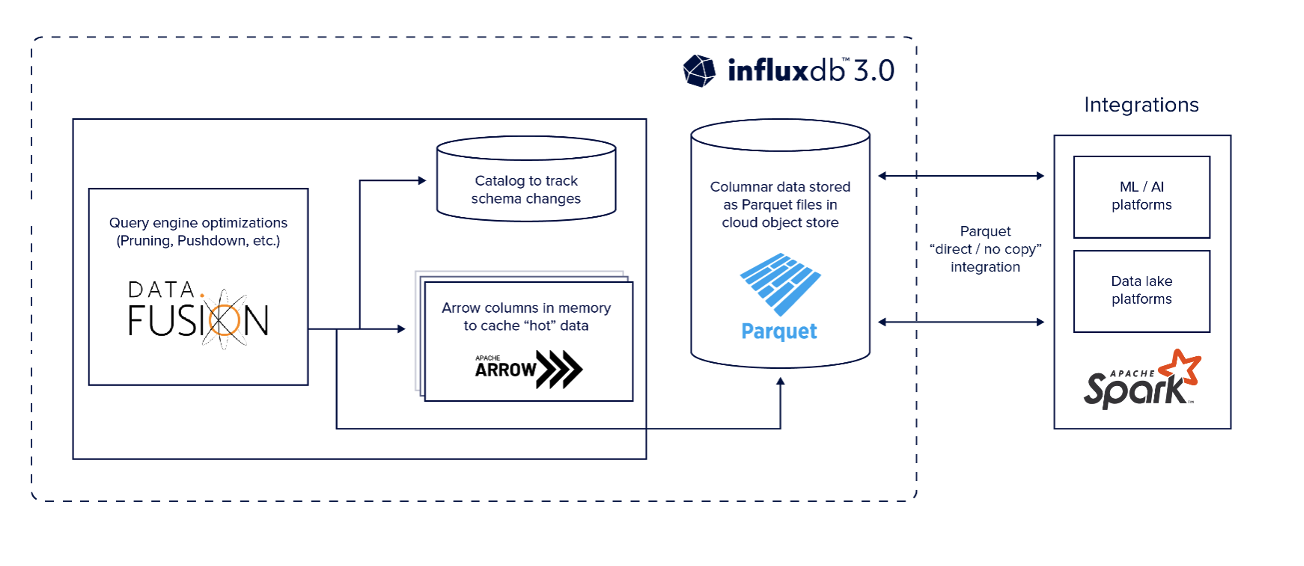 InfluxDB 3.0 architecture diagram
InfluxDB 3.0 architecture diagram
InfluxDB 3.0 unlocks new use cases such as storing metrics, events, and traces by supporting unlimited cardinality. Customers can operate their systems with huge amounts of cardinality, in the tens or even hundreds of millions plus, without facing limitations. Queries are 100x faster and those including high cardinality data 5x to 45x faster. Check out our benchmarks for more details.
InfluxDB Clustered
InfluxDB Clustered is the next evolution of InfluxDB Enterprise. Clustered is a self-hosted, self- managed instance of InfluxDB that customers can deploy on their own infrastructure. Clustered is a Kubernetes-based solution, leveraging underlying Kubernetes fundamentals. We created Clustered with large enterprises in mind. These organizations typically look for performance at scale, need better control over their data and underlying infrastructure, and require enterprise-grade security.
Clustered customers can fine-tune their database controls to meet their specific performance, regulatory, or business requirements for data storage and processing. Customization also includes environments – Clustered will run anywhere Kubernetes does. Each workload is tunable based on its individual criteria and optimized for performance, scale, and/or cost.
Watch the webinar!
Introducing InfluxDB Clustered does deep technical dives on compression and queries, including a Clustered product demo that starts at 28:43, and a Q&A that starts at 52:13. The Q&A includes detailed questions about compression optimizations, the best practices for schema design when considering unlimited cardinality, and the future of Edge Data Replication.
If you have questions or would like to speak with someone on our sales team, you can contact someone here. For more about InfluxDB, check out our blog or sign up for a free cloud account.
