Tracing with InfluxDB IOx
By
Jason Myers /
Jacob Marble /
Product, Use Cases
Nov 30, 2022
Navigate to:
Tracing has always been a key use case for time series data. But admittedly, it’s also one that past versions of InfluxDB could not handle as well as we wanted. One of the roadblocks was the cardinality issue. Tracing data is, almost by definition, high cardinality data and prior to InfluxDB IOx, high cardinality data could affect query performance.
InfluxDB IOx removes limits on cardinality, opening up the InfluxDB platform to handle a wider range of use cases, like traces and logs, in a performant manner. So, let’s answer some basic questions about tracing and address how InfluxDB IOx makes them possible.
What is tracing?
When you have a distributed system, generally, you want to know how all the different components are functioning in relation to each other. Some processes and services may be dependent on other ones, so errors, delays, and bottlenecks can impact overall system performance.
To understand how all these different pieces work in concert with each other we use a form of observability called tracing. A trace provides a view of a request, task, operation, job, or other useful unit of work, as it works its way through a distributed system. Any number of subtasks, (algorithms, network calls, database transactions, cache queries, etc) coordinate to satisfy the request. Each of these subtasks is a span.
So, a trace is a collection of spans that provide timing information on the finer details of a request.
How does tracing work?
Spans have zero to many sub-spans, called child spans, or children. A child span can have its own children, and so forth.
A trace begins with a root span, and has no parent. Because the root span is the recursive parent of all other spans in the trace, the duration of the root span represents the total time of the trace.
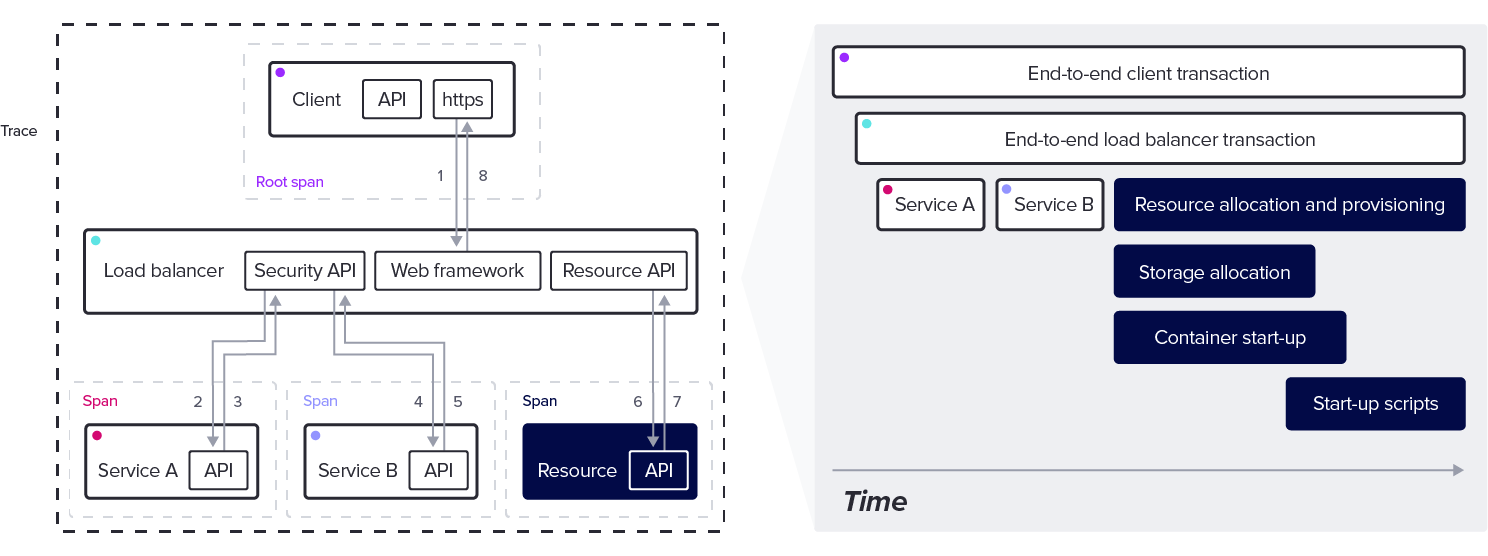
As indicated in the diagram, there are a lot of potential spans in a single trace.
To construct a trace from all these spans, and to ensure that everything fits together properly, every span needs identifying information. To that end each span has a trace ID, a span ID, and, when applicable, a parent span ID.
These building blocks create a hierarchical tree of subtasks that provide the key structure for building traces.
What does this have to do with cardinality?
Before IOx, InfluxDB’s time series merge tree (TSM) stored data in columns of series. A series is a unique combination of measurement, tags, and one field. In this model, cardinality is the total number of series, i.e., the number of columns stored on disk. So, if you have two series, your cardinality is two. High cardinality usually becomes troublesome because it correlates with slower query performance.
To avoid runaway cardinality in pre-IOx InfluxDB, the quantity of series must be bounded. The challenge with tracing is that each trace and span generate a unique ID (for tracing, most database schemata consider these IDs to be tags), creating unbounded tag values. Combine this with the volume and velocity of tracing data and you get runaway cardinality.
IOx: Solving for cardinality
Previous versions of InfluxDB stored each series as a column, which could result in a lot of columns. With the introduction of InfluxDB IOx, the measurement timestamp, tags, and fields all get saved to a respective column, so a measurement with two tag keys and three fields is represented by six columns. This design drastically reduces the number of columns the database has to deal with.
IOx stores the columns of a table in a Parquet file. When more data arrives, IOx writes those columns of the table to a new Parquet file. Parquet files compress columns of data very well, and IOx stores those files in object storage (S3), which is extremely scalable. The InfluxDB Cloud query tier automatically scales with your query workload.
The Parquet file format also provides fantastic query performance. For example, when IOx writes columns of data to Parquet, it includes hints in the Parquet metadata to describe column contents. This way, the query engine can skip over entire Parquet files, and/or unhelpful portions of Parquet files, at query time.
These updates to the InfluxDB storage engine, persistence format, and storage and query tiers combine to provide infinite cardinality and unlock use cases like tracing.
To get started with InfluxDB IOx and see what unlimited cardinality can unlock for you, sign up for the InfluxDB IOx beta program.
