TL;DR InfluxDB Tech Tips — Aggregating across Tags or Fields and Ungrouping
By
Anais Dotis-Georgiou
Product
Use Cases
Developer
Aug 16, 2021
Navigate to:
So you’re interested in time series databases, and you decided to explore InfluxDB Cloud or InfluxDB v2. Perhaps you just created a free account or downloaded the binary, and now you’re playing around with the InfluxDB User Interface (UI) and learning Flux. The hardest thing for beginners to understand are the return results from a Flux query or Annotated CSV. A detailed explanation of an Annotated CSV is provided in this blog TL;DR InfluxDB Tech Tips – How to Interpret an Annotated CSV, but today we’ll focus on understanding the group key and how it affects the table stream. In other words, we’ll learn about:
- How to use a sample dataset to explore Flux
- What the group key is and how the group key determines the number of tables in your Annotated CSV output
- How you can use the group() Flux function to change the group
- How you can perform aggregations across fields or measurements by taking advantage of the group() function to both group and ungroup your data
The TL;DR for this TL;DR: ungroup data with an empty group() Flux function
If you’re already familiar with the bullets in the section above, and you just want a quick answer to the following problem: you just want to know how to perform an aggregation across tags, but you’re flummoxed because your data is in separate tables. Apply |> group() to your Flux query before you perform the aggregation to ungroup the data. If you’re still confused, continue reading.
Use sample data to explore Flux
The easiest way to get started with InfluxDB is to choose a sample data and write it to InfluxDB with Flux. Today we’ll use the NOAA water sample data. This dataset is fairly large, so we’ll go ahead and actually write the data to our InfluxDB instance. In order to write the data, we first create a destination bucket which will store our sample data. You can create a new bucket with the InfluxDB UI or with the API.
 <figcaption> A screenshot of the Load Data page in the InfluxDB UI.</figcaption>
<figcaption> A screenshot of the Load Data page in the InfluxDB UI.</figcaption>
Click on Data in the menu on the right. Then navigate to the Buckets tab. Finally, click + Create Bucket to create your bucket and name it. Today we’ll name ours “noaa”.
As per the sample data documentation, we’ll copy and paste the following Flux code into our Script Editor in the InfluxDB UI:
import "experimental/csv"
relativeToNow = (tables=<-) =>
tables
|> elapsed()
|> sort(columns: ["_time"], desc: true)
|> cumulativeSum(columns: ["elapsed"])
|> map(fn: (r) => ({ r with _time: time(v: int(v: now()) - (r.elapsed * 1000000000))}))
csv.from(url: "https://influx-testdata.s3.amazonaws.com/noaa.csv")
|> relativeToNow()
|> to(bucket: "noaa", org: "example-org") <figcaption> A screenshot of the Script Editor in the InfluxDB UI.</figcaption>
<figcaption> A screenshot of the Script Editor in the InfluxDB UI.</figcaption>
Click the Query Builder button to return back to the Query Builder. Clicking the Submit button allows you to run the Flux query.
For the purposes of this TL;DR, ignore most of that Flux. All we need to understand is that you need to edit the last line with the to() function:
- Replace the bucket parameter with the name of your destination bucket.
- Replace the org parameter with the name of your org. In InfluxDB Cloud, your org is the email you used to sign up for an account.
The group key and how it determines the number of tables in your Annotated CSV output
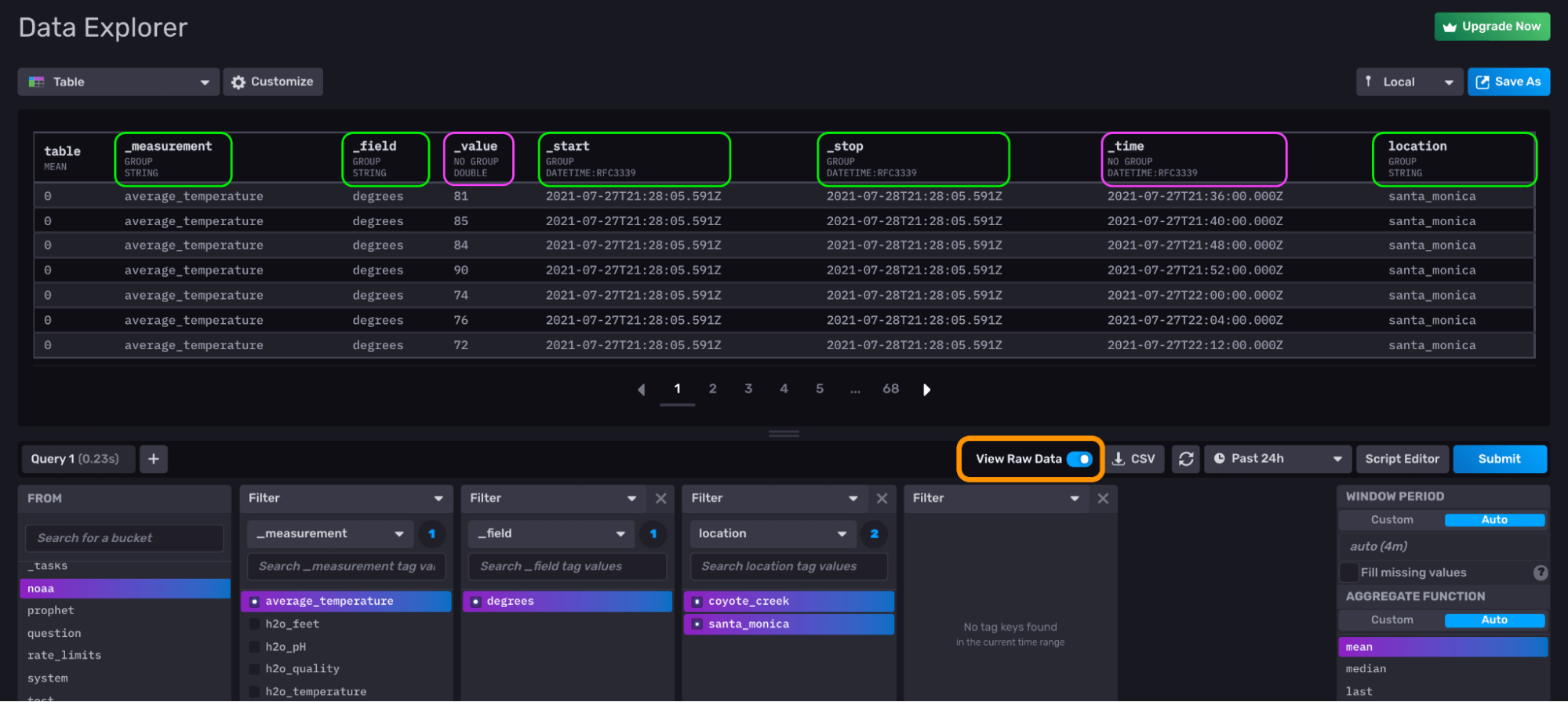
Use the Query Builder to get the average_temperature data from santa_monica and coyote_creek. Toggle View Raw Data (orange) on to see the Annotated CSV and the group key. Columns are assigned a group key annotation value of either true (highlighted here in green) or false (pink) when the values in that column are all the same (green) or not (pink), respectively.
Query for some of your data, and toggle View Raw Data to “on” in order return the Annotated CSV output. An Annotated CSV output is a stream or collection of tables. The group key defines the size and number of tables. The group key annotation is a boolean that determines whether or not the value in a column is the same in each row. Columns that have a group key annotation with a value of true are part of the group key.
In the picture above, we queried for average temperature data from two locations. Specifically we queried for:
- 1 measurement, "average_temperature".
- 1 field, "degree"
- 2 "location" tag values, "coyote_creek" and "santa_monica"
This translates to the following Flux code as viewed by the Script Editor.
from(bucket: "noaa")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "average_temperature")
|> filter(fn: (r) => r["_field"] == "degrees")
|> filter(fn: (r) => r["location"] == "coyote_creek" or r["location"] == "santa_monica")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")The columns of our Annotated CSV output include:
- Table: this column assigns a numeric value to a table in the table stream in the order that it was returned. Since we queried for two tag values, "coyote_creek" and "santa_monica", we will get two tables back.
- _measurement: the measurement for the data we queried for–"average_temperature"
- _field: the field key for the data we queried for–"degrees"
- _value: the field values for the data
- _start: the start date of our query
- _stop: the stop date of our query
- _time: the timestamp of our time series
- location: the tag key we queried for
Underneath those column names is the group key subheader. A column is part of a group key when every row in that column is the same. Columns that are part of the group key are given the subheader “GROUP” while columns that are excluded from the group key are given the subheader “NO GROUP”.
By default, InfluxDB includes the following columns as a part of the group key:
- _measurement
- _field
- _start
- _stop: the stop date of our query
- Any tag key columns
These columns are included as part of the group key by default so that a single table is output for each time series. A series is defined by the unique combination of measurement(s), tag set(s), and field key(s). The UI graphs each table as a separate line.
Now imagine that you want to find the sum of all of the values across the two locations, so you add the sum function like so:
from(bucket: "noaa")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "average_temperature")
|> filter(fn: (r) => r["_field"] == "degrees")
|> filter(fn: (r) => r["location"] == "coyote_creek" or r["location"] == "santa_monica")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> sum()That query will return the following result:

The sum() function gets applied to each table in the steam, so we end up getting the sum for each location instead of our desired result: the total sum across the two locations.
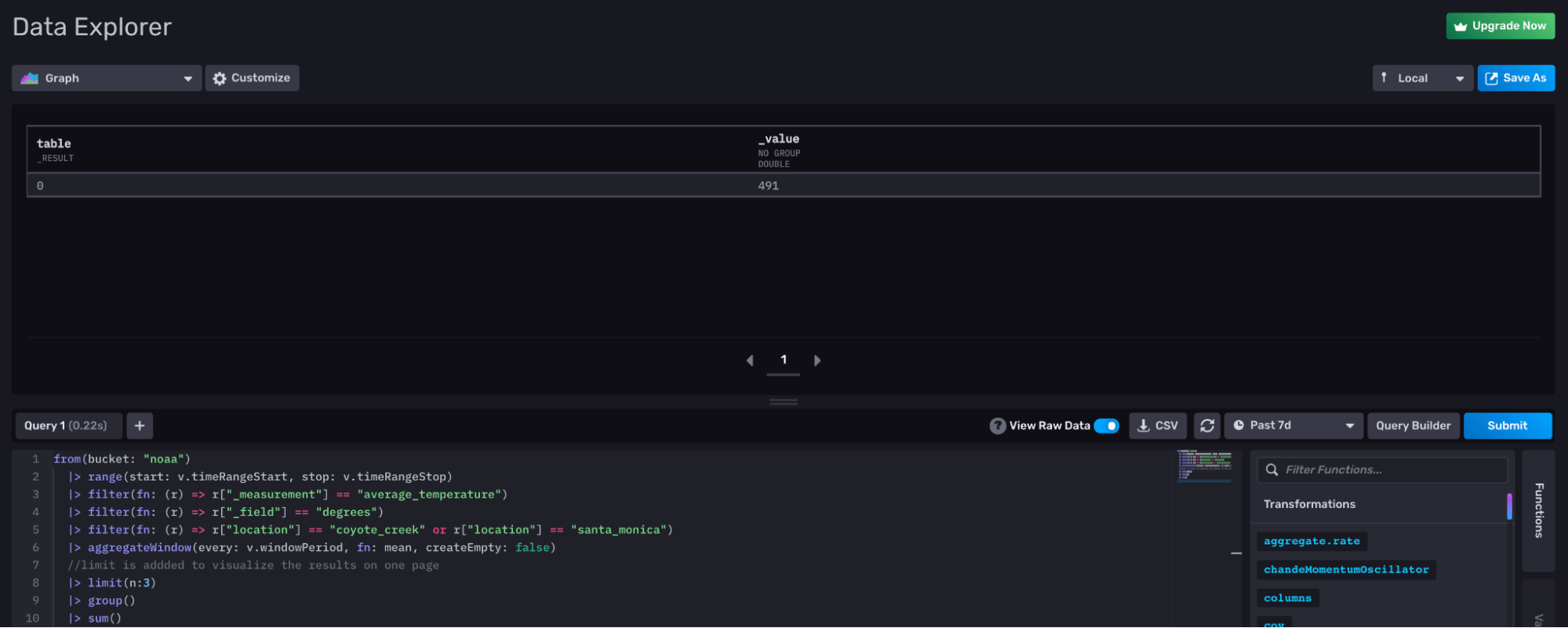
In order to correct this, we must first combine the two tables in the stream into one table. There are several ways to achieve this goal, but the easiest way is to eliminate the “location” column from the group key. Applying an empty group() function without passing in any columns to the function will effectively ungroup our data. In other words, the following Flux query:
from(bucket: "noaa")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "average_temperature")
|> filter(fn: (r) => r["_field"] == "degrees")
|> filter(fn: (r) => r["location"] == "coyote_creek" or r["location"] == "santa_monica")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
//limit is addded to visualize the results on one page
|> limit(n:3)
|> group()Produces the following Annotated CSV output:

Notice that our two tables are combined into one table and none of the columns are part of the group key. Now if we add a sum() to the end of our Flux query we can achieve our initial goal and obtain the total sum:
Conclusion
I hope this InfluxDB blog post helps alleviate some confusion around:
- What Annotated CSV is
- How the group key affects the table stream output
- And how to ungroup your data to perform aggregations across fields, tags, and tables in a stream
If you are using the InfluxDB v2 and need help, please ask for some in our community site or Slack channel. If you’re developing a cool IoT application or monitoring your application on top of InfluxDB, we’d love to hear about it, so make sure to share your story! Additionally, please share your thoughts, concerns, or questions in the comments section. We’d love to get your feedback and help you with any problems you run into!
Further reading
While this post aims to provide a comprehensive overview of how to aggregate across fields, tags, or table streams; the following resources might also interest you:
- TL;DR InfluxDB Tech Tips – How to Interpret an Annotated CSV: This post describes how to interpret an Annotated CSV, the Flux query result format for InfluxDB.
- Getting Started with Python and InfluxDB v2.0: This post describes how to get started with the Python Client Library.
- Getting Started with InfluxDB and Pandas: This post shares how to get started with Pandas to write dataframes to InfluxDB and return dataframes with a Flux query.
- Top 5 Hurdles for Flux Beginners and Resources for Learning to Use Flux: This post describes common hurdles for Flux beginners and how to tackle them by using the InfluxDB UI, understanding Annotated CSV, and more.
- Top 5 Hurdles for Intermediate Flux Users and Resources for Optimizing Flux: This post describes common hurdles for intermediate and advanced Flux users while providing more detail on pushdown patterns, how the Flux engine works, and more.
