Powering Real-Time Data Processing with InfluxDB and AWS Kinesis
By
Anais Dotis-Georgiou
Developer
Feb 14, 2024
Navigate to:
Imagine a data engineer working for a large e-commerce company tasked with building a system that can process and analyze customer clickstream data in real-time. By leveraging Amazon Kinesis and InfluxDB, they can achieve this goal efficiently and effectively.
So, how do we get from idea to finished solution? First, we need to understand the tools at hand. To that end, we’ll explore the benefits of InfluxDB 3, including its ability to handle vast amounts of data for real-time analytics applications. Then we’ll dive into how to effectively use InfluxDB with Amazon Kinesis, a scalable and fully managed platform for ingesting and processing streaming data, by using Telegraf, an open source collection agent for metrics and events.
Advantages of InfluxDB 3
If you have a lot of devices that generate time-stamped data, then you need a time series database. Optimized to store and query data in real-time and at scale, InfluxDB 3 offers unrivaled performance for your time series data. It can ingest millions of data points per second without impacting performance. Some additional benefits include:
- Built on the Apache Arrow ecosystem, it provides interoperability with open source solutions, including visualization, ETL, and data science tools.
- Version 3 delivers significant performance improvements over previous versions, as described in this benchmark.
- Full SQL support, which means there’s a minimal learning curve for many developers. This allows teams to efficiently extract insights and enhance overall productivity.
- Unlimited cardinality. Check out the video at the link, but cardinality relates to the volume of data your database can handle in relation to that database’s performance. Unlimited cardinality support means that InfluxDB 3 can handle large, complex datasets without impacting performance.
- InfluxDB 3 can store metrics, traces, and logs in a single place.
Leveraging Amazon Kinesis with InfluxDB
AWS Kinesis excels in real-time data processing, crucial for real-time analytics, IoT, video stream processing, and other time series use cases. Its scalability makes it ideal for fluctuating traffic volumes, while seamless integration with AWS services like Lambda and S3 facilitates efficient data handling within the AWS ecosystem. Moreover, Kinesis is cost-effective with its pay-as-you-go model, catering to businesses of varied sizes and needs.
So, we know a bit about InfluxDB and Kinesis and that InfluxDB can handle all our time series data. How do we go about building our real-time analytics application?
We need to set up Telegraf to collect data from an Amazon Kinesis stream and write it to an InfluxDB 3 Cloud Serverless instance. Fortunately, Telegraf already has a Kinesis plugin.
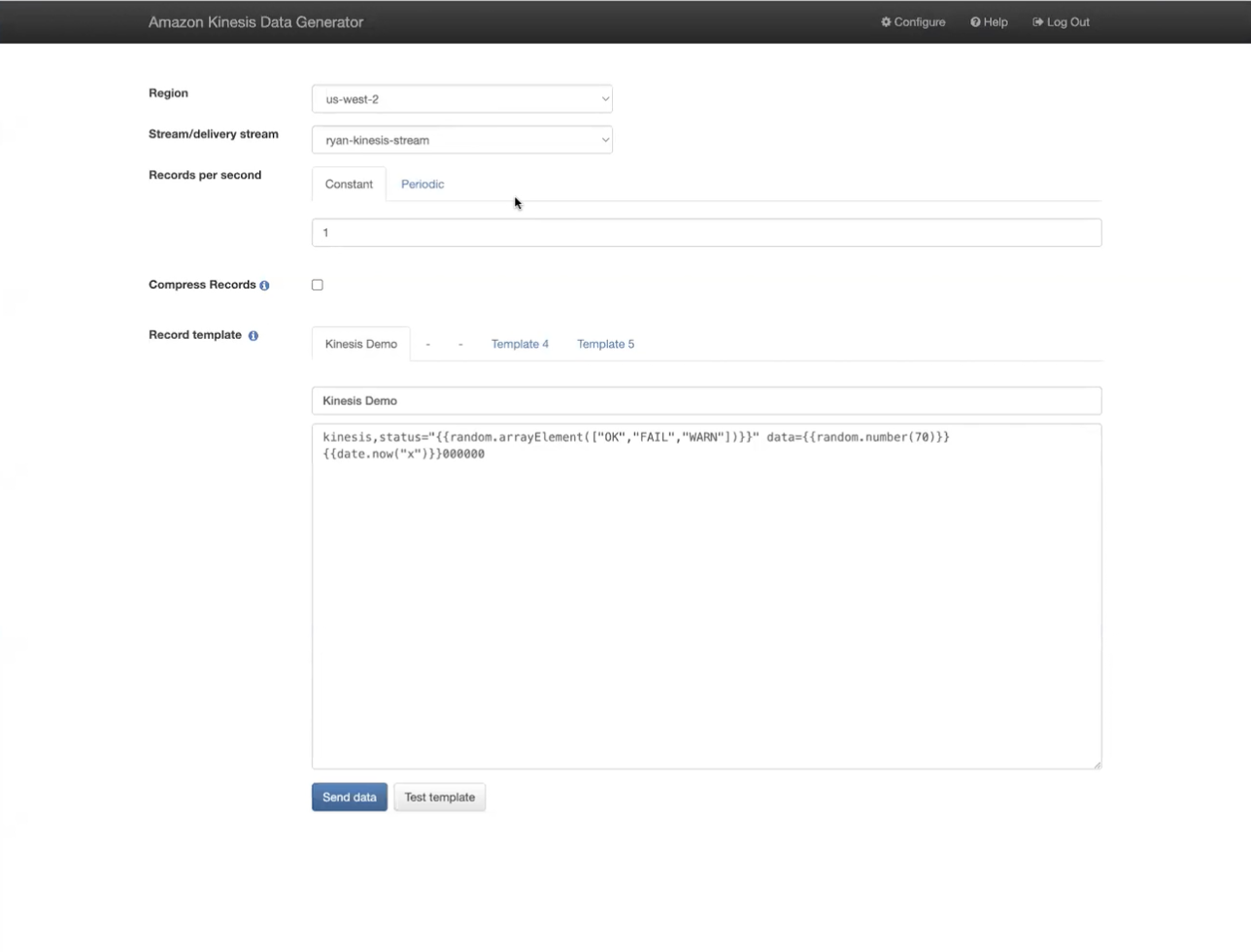
For this example, we use the Amazon Kinesis Data generator to send line protocol data to the Kinesis stream. The Telegraf agent uses the Kinesis input plugin to collect data from the stream and the InfluxDB output plugin to send that data to storage.
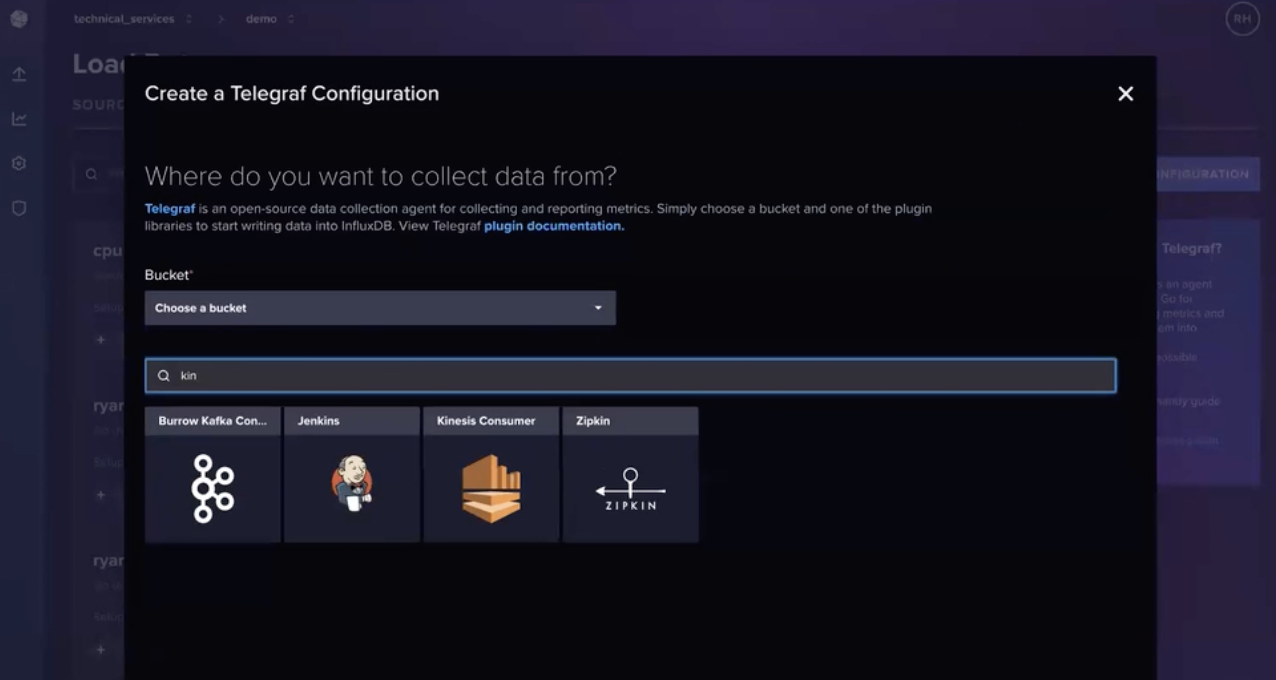
You can use the InfluxDB Cloud Serverless UI to create and host Telegraf configurations. The screenshot above shows a search for the Kinesis Consumer Input Telegraf Plugin in the InfluxDB UI. Once you select that plugin, you can also edit the configuration directly in the UI:

To configure the Kinesis plugin, include the region that hosts the Kinesis stream, access key, secret key, stream name, and shard iterator type. Finally, specify the data format type. Because the data in the stream is in line protocol, the native input format for InfluxDB, we can simply select data_format=influx.
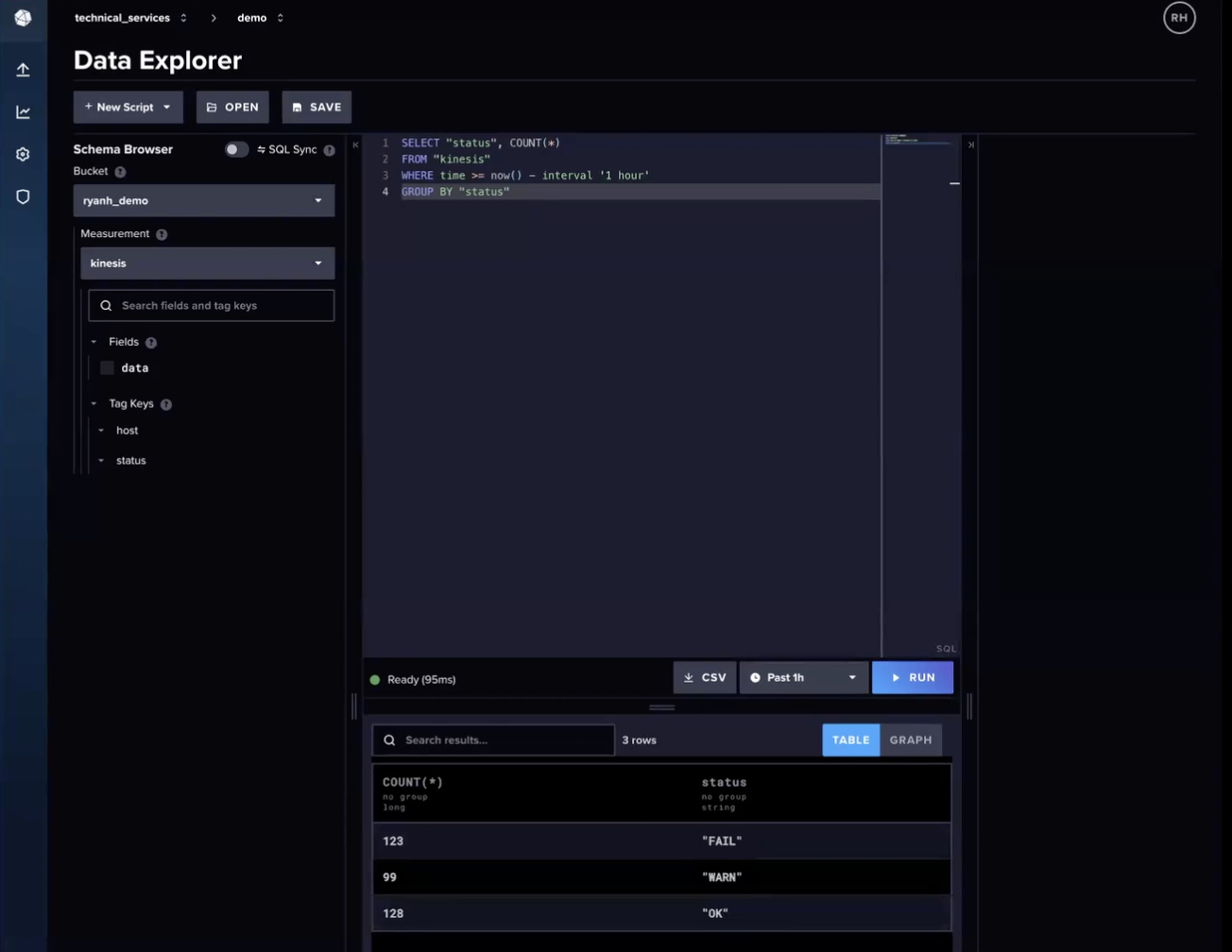
Finally, we can query our data with SQL in the Data Explorer in the InfluxDB Cloud Serverless UI. The image above shows an example of querying our data for state count using the following SQL query:
sql
SELECT “status”, COUNT(*)
FROM “kinesis”
WHERE time >= now() - intergral ‘1 hour’
GROUP BY “status”
Additional resources
If this blog piqued your interest, you might also enjoy learning how to use AWS Fargate with InfluxDB. AWS Fargate is “a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters of Amazon EC2 instances.” I encourage you to check out this repo that contains a containerized solution for creating downsampling tasks with InfluxDB. You can easily run the container on AWS Fargate and schedule your tasks this way to generate cost savings.
Get started with InfluxDB Cloud 3 here. If you need any help, please reach out using our community site or Slack channel.
Prefer to watch a video? Catch our InfluxDB and AWS on-demand demo here.
