MQTT vs Kafka: An IoT Advocate’s Perspective (Part 2 – Kafka the Mighty)
By
Jay Clifford
Use Cases
Developer
Apr 25, 2022
Navigate to:
In Part 1 of this series, we started to compare the uses of Kafka and MQTT within an IoT infrastructure. It was concluded that in a basic publish-and-subscribe model of an IoT device, Kafka might simply be overkill. However, we also learned that Kafka has some valuable features we would like to utilize within an IoT architecture:
- Schema design
- High availability
- Data persistence and durability
In this post, I want to focus on redesigning our last demo to make use of some core Kafka features that we overlooked (topic design and partitioning), as well as introduce new topics (pun intended) like third party integrations.
Before we begin here is a little housekeeping:
Topics and partitioning
Within our original demo, our topic structure looked like this:
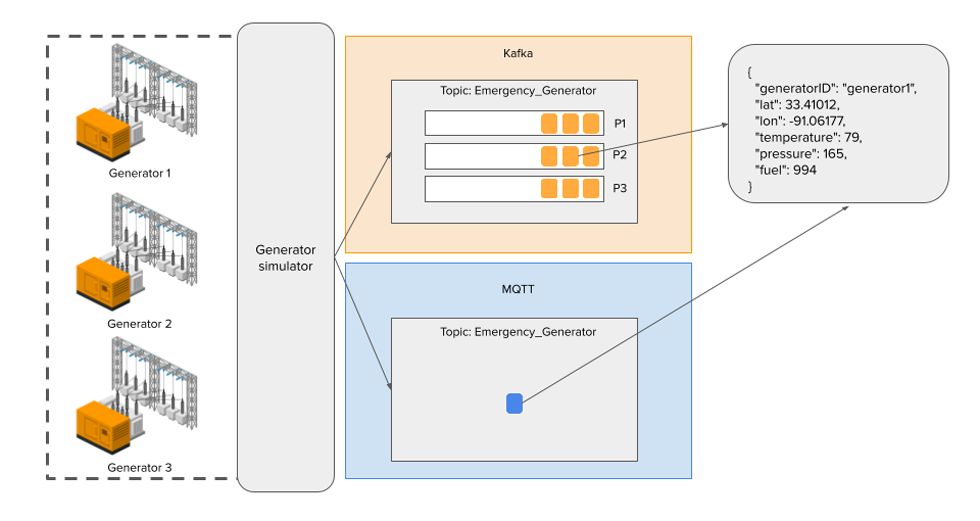
Essentially no matter how many Emergency Generators we spun up, our payloads were all handled by the same topic. Under a finite number of generators, this is reasonable. However, this does leave us with a few clear issues:
- The consumer must imply its own logic to process/ignore payloads. For example, a consumer might only be interested in processing data from Engines 1 - 2 or based on a specific region.
- Performance is also affected since our consumers will have to handle all messages rather than a specific subset.
So what could we do differently?
MQTT
So within MQTT, we can establish a topic hierarchy. The team at HiveMQ wrote a great blog post outlining some of the do’s and don’ts when building out topics:
- Never use a leading forward slash
- Never use spaces in a topic
- Don’t subscribe to #
- Don’t forget extensibility
- Use specific topics, not general ones
I highly recommend checking that post.
So let’s deploy some of this logic to our application. Currently, our payload looks like this:
{'generatorID': 'generator4', 'lat': 40.65995, 'lon': -111.99633, 'temperature': 74, 'pressure': 198, 'fuel': 901}Our topic is as follows:
emergency_generator
Since we have the generatorID available within the payload, we can look to append this as a new topic layer:
def publish_to_topic(self, topic: str, data: dict):
topic = topic +"/"+ str(data["generatorID"])
message = json.dumps(data)
self.client.publish(topic, message)This gives us our emergency_generator topic and the subsequent layers underneath:
emergency_generator/generator1
emergency_generator/generator2
emergency_generator/generator3Using this hierarchy structure provides the added benefit of natural division between devices (in our case generators). Can we achieve a similar architecture to Kafka? Are there added benefits?
Kafka
Kafka has a pretty simple and powerful way of naturally segregating our data streams. Let’s take a look at this section of code again:
self.p.produce(topic=topic, key=str(uuid4()), value=data, on_delivery=delivery_report)As part of our data publish, we assign a key. This key is assigned to our data as a key-value pair. Although this key is optional, it is extremely powerful when combined with partitions. We will get to this in a second, but let’s first update our key to use our generatorID instead.
self.p.produce(topic=topic, key=str(data['generatorID']), value=data, on_delivery=delivery_report)Now for the interesting part, we said in Part 1of this blog series that Kafka deploys some unique features for processing vast quantities of data in an efficient way. This is where partitions come in. You can imagine partitions like a simple queue for records (our data). Partitions have the benefit of providing consistent ordering of records and parallelism for performance purposes, but how? This is where our key comes in. A great way to imagine this is an airport immigration queue, and your passport is the key. There is usually a queue (partition) for country nationals, fast-track such as European passports and all passports. All passport holders will enter their respective queues for processing. This is equivalent to our Kafka architecture Generator1 records will always enter for example partition 1 and Generator2 partition 2. Although there is not usually a 1-to-1 relationship between keys and partitions, there are some great benefits as we scale. They include:
- Topic parallelism: suppose our Generators were producing 1000 records per second. We have a microservice trying to consume those messages and perform some logic. We know the microservice can only handle 500 records a second so our consumer will never be able to achieve consistency with our producer. Instead, using partitions we can spin up a second or even third instance of our microservice to consume a portion of those records in parallel to one another. Achieving a much higher throughput.
- Topic replication: this allows us to reserve partitions for holding copies of our records. Since our topics are capable of being distributed over many servers (like Kubernetes) this helps to prevent data loss due to outages. If one partition is unreachable then our consumer will simply take records from the backup partition instead.
As you can see we are starting to utilize some of the powerful features which set Kafka apart from other pub-sub messaging protocols.
What else can Kafka do?
Apache Kafka is an enterprise messaging protocol that understands it needs to fit within a pre-existing ecosystem to be effective. This is where Kafka Connect comes in.
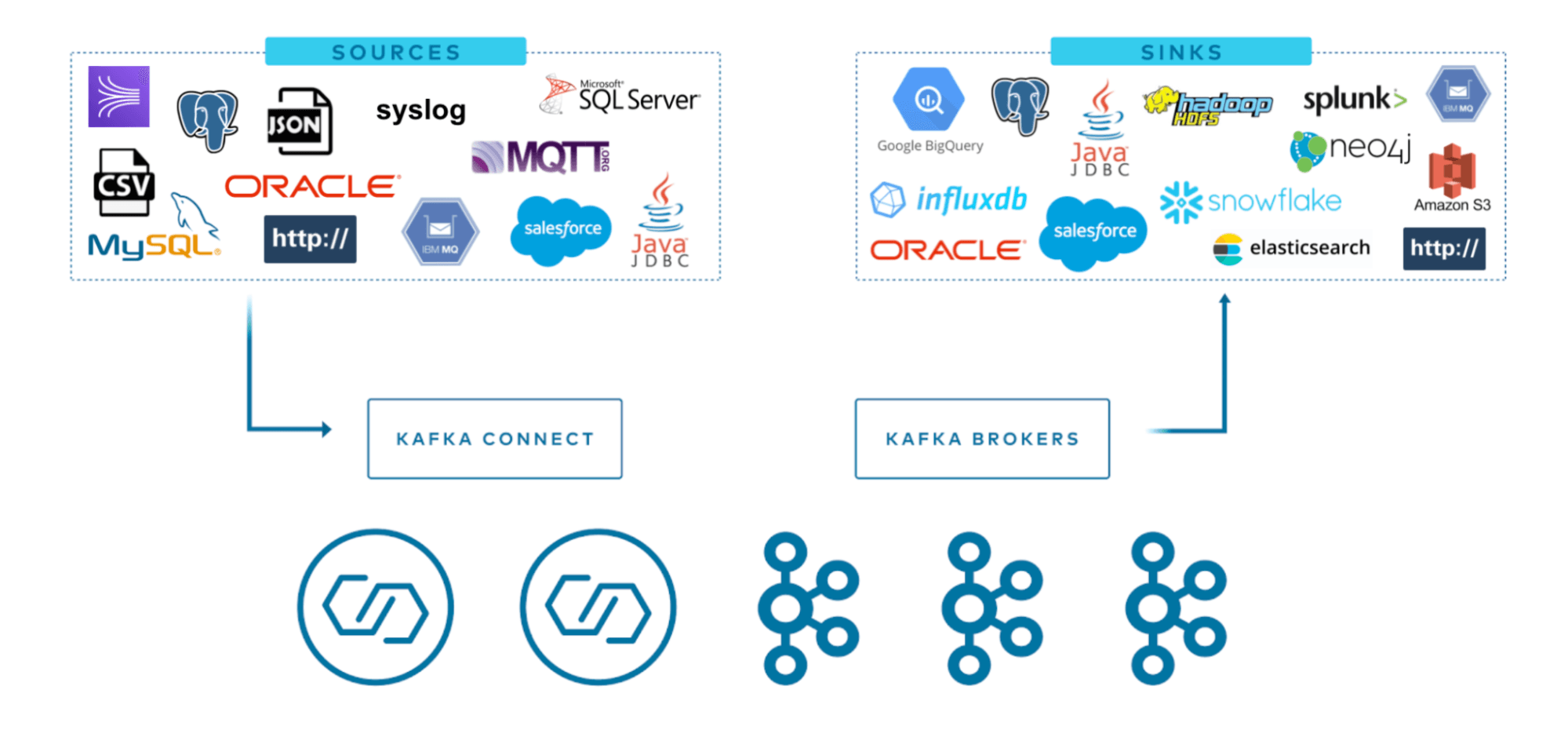
Kafka Connect provides a catalog of powerful premade connectors for well-known enterprise systems and data storage engines like InfluxDB. So since I am biased let’s discuss sources and sinks using the InfluxDB plugin.
Kafka Connect splits connectors into two categories:
- Sources: Places where we can pull our data from and write them into Kafka topics.
- Syncs: Places where we can write our data from topics to.
We are going to park the InfluxDB source for now (spoiler alert I am going to use this within part 3 of the blog series). Let’s set up an InfluxDB sync:
Note: For ease of demoing I am using Confluent Cloud: https://confluent.cloud/
- Under Data integration head to Connectors and search for InfluxDB.
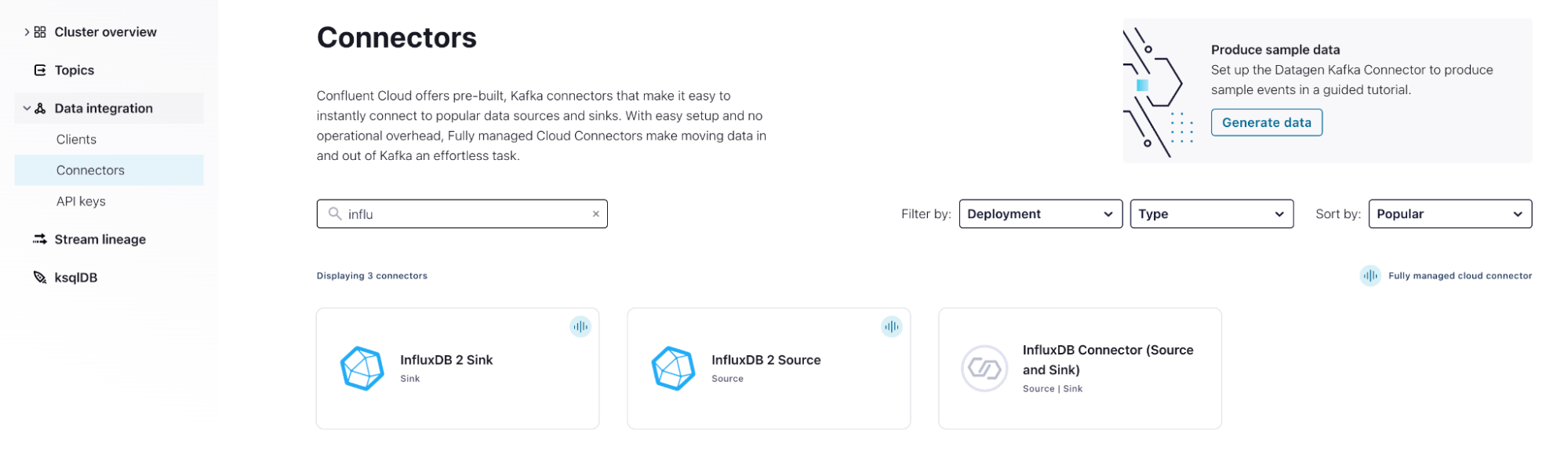
- Select InfluxDB 2 sink
- Now we can start to configure our connector. This is pretty standard, here is a snapshot of mine:

The breakdown is as follows:
- The Topic(s) we wish to subscribe to. In our case, it is only one, emergency_generators
- Max Tasks this is equivalent to the microservice concept we discussed earlier. Since we are using the free tier of Confluent Cloud we are bound to one.
- Kafka service authentication for security (stops rogue services trying to connect to your data streams).
- The InfluxDB instance we wish to point to.
- The org of our InfluxDB instance.
- The bucket where we store our data.
- Writing precision (seconds, milliseconds, etc.).
- The measurement format. We have opted to use the topic name as our InfluxDB measurement name.
You should now be able to deploy the connector. We can then view the data flow within the stream lineage.
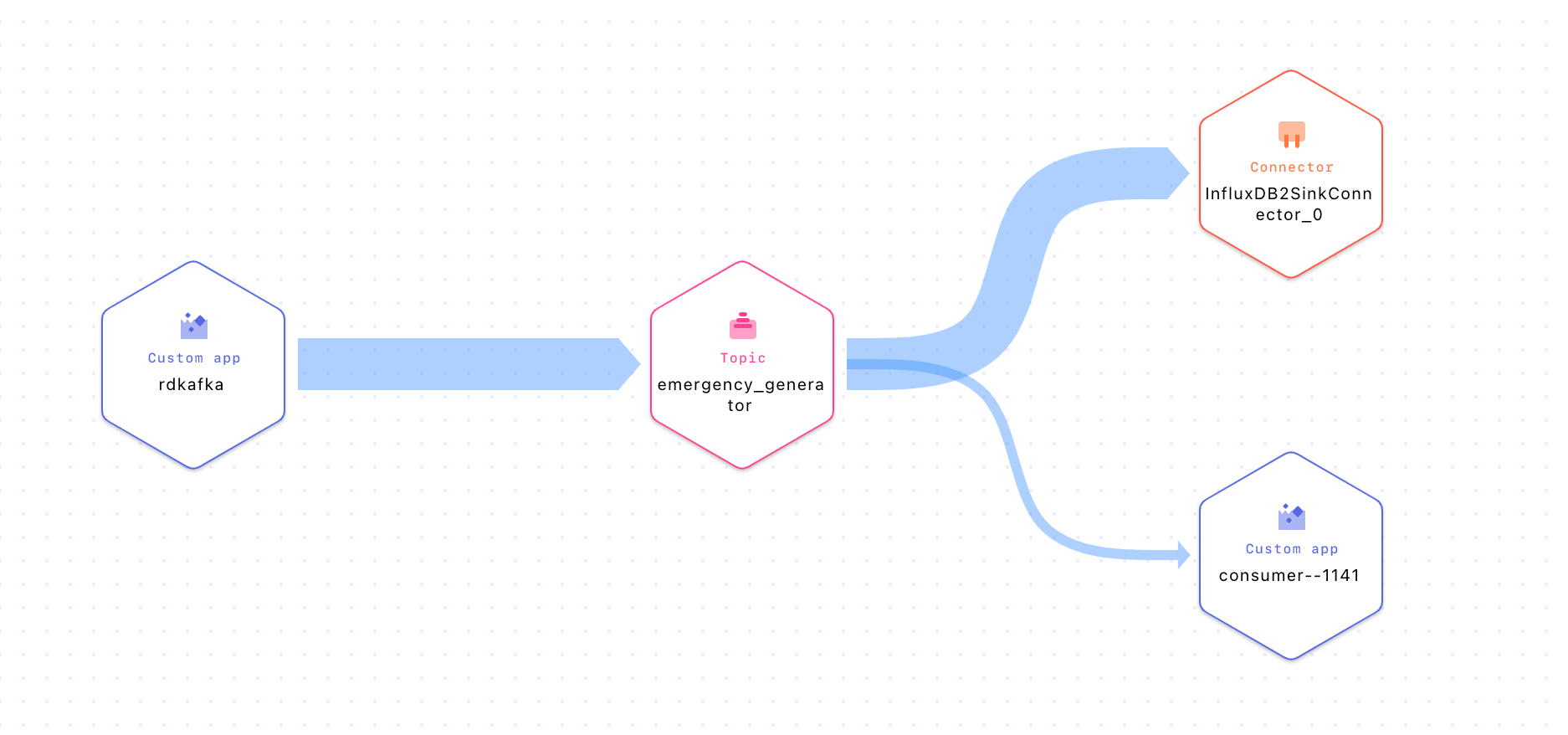
InfluxDB is one of many connectors that Kafka Connect has. Our JSON payload is relatively simple meaning it translates directly to a lot of connectors that accept JSON payload structures. However, Kafka can also apply simple transformations to data payloads for on the fly conversion helping to improve interoperability.
Prospective and conclusion
We have now delved a little deeper into the deployment architectures of both MQTT and Kafka. Although MQTT and Kafka both use Topics to describe containers for message payloads, we now see under the hood they are quite different. From my perspective, I can now see the performance implications of using Kafka partitions and record keys. We have also explored the ability to use enterprise-grade connectors offered by InfluxDB. All of this in mind this still does not outweigh some of the shortfalls of a Kafka only IoT solution:
- Kafka is built for stable networks which deploy a good infrastructure
- It does not deploy key data delivery features such as Keep-Alive and Last Will
Places where MQTT excel. So what next?
Join me for the final blog in this series, where we combine what we have learned to create a truly hybrid IoT architecture using a real IoT use case. We will learn about Kafka’s MQTT proxy and further explore Kafka’s enterprise connectors such as InfluxDB source.
