"Metrics First" Approach to Log Analysis
By
Tim Hall /
Product, Company, Use Cases, Developer
Jun 14, 2018
Navigate to:
We just completed an annual survey of our community members along with our InfluxDB Enterprise and InfluxDB Cloud customers. For those of you who participated in the survey, thank you for taking the time to submit your responses. We hope you enjoy your new socks!
Within the survey results, we see that 27% of you are already using InfluxDB for collecting and analyzing logs as well as numerical metrics and events. We think you will find our latest enhancements to Telegraf and Chronograf very interesting and for those that aren’t…read on!
As you leverage metrics as your early warning system for detecting anomalies, you are likely digging in deeper to other available contextual data that helps guide you to resolve issues that appear with the things you are monitoring and managing; across applications, systems, sensors, databases, and more. This likely means that you’ve got a tremendous amount of non-metric data, often referred to as “digital exhaust”, in the form of log files.
From the more than 50+ log management tools out there – and there is some very fine technology that exists – there are many, many options for collecting and searching the exhaust in the hopes of discovering something important or valuable. If you spend time with your systems and its log files, you build up knowledge about what the various messages mean, why these events were triggered, and mentally correlating important lines of information based on patterns you see resulting from issues you’ve had to deal with. But why??
InfluxData believes in a “metrics first” approach to monitoring and management. What this means is that the metrics are your guide. Gathering of metrics provides you with baseline telemetry data that tells you about the health of the various components of your systems, applications and sensors. These metrics also point out when you begin to deviate from the norm, what parts of the system are impacted, and supply valuable metadata to supplement the graphical representation of the metrics themselves. Having access to log data is a secondary and an important contextual source to help you further triage and resolve issues. At some point, the count of errors or deviation against a norm isn’t enough: you need to see the actual log details in order to diagnose the issue. But as someone who operates a large number of applications, sensors or systems, you shouldn’t have to “guess” at where and when to look for problems using logs alone and you shouldn’t need to open another, separate tool to get that detail.
Introducing Syslog Parsing in Telegraf 1.7
To help address this kind of challenge for our customers and community members, we have released Telegraf 1.7. Specifically within the Telegraf 1.7 release, we have added a high-performance syslog plug-in to allow for log collection and storage with any of the output sources that Telegraf supports. For those of you already using syslog as the means to collect your logs, we encourage you to give this a try.
Now, log files contain collections of events and these events are typically time-stamped – guess what is a great piece of technology to collect, analyze and act on time series data?
If you said, InfluxDB… good for you! But, based on the survey results, many of our community members and customers haven’t used InfluxDB as the place to accumulate their log events. The Telegraf logparser plug-in has existed since the 1.0 release and it supports the ability to parse grok-style log patterns. This can be a powerful approach to addressing distributed log files and collecting them with InfluxDB, but so many folks are collecting logs using the syslog protocol that it made sense to add this additional mechanism to tap into that protocol and simplify the gathering of log data via Telegraf. Plus, we worked hard to make this really fast and efficient.
Viewing Logs in Chronograf
We aren’t stopping there! With the introduction of Chronograf 1.5, we delivered the ability to visualize non-metric data in tabular format. For those of you who use the combination of Telegraf, InfluxDB and Chronograf, that means it should be easy to quickly visualize log data within dashboards too. Use the available metrics, metadata, and time ranges available within Chronograf to pinpoint the amount of log data you want to see – based on specific deviations from the norm. If you want to see some log events related to the specific dashboard time being displayed, you can modify the query extracting the log data to include shared metadata from your metics along with the dashboard time and automatically filter the logs to the relevant set. No need to guess at search criteria! However, for those who still wish to explore their logs in more detail, the upcoming release of Chronograf includes a log visualization component. You can begin exploring this nowvia the nightly build for Chronograf available on the downloads page.
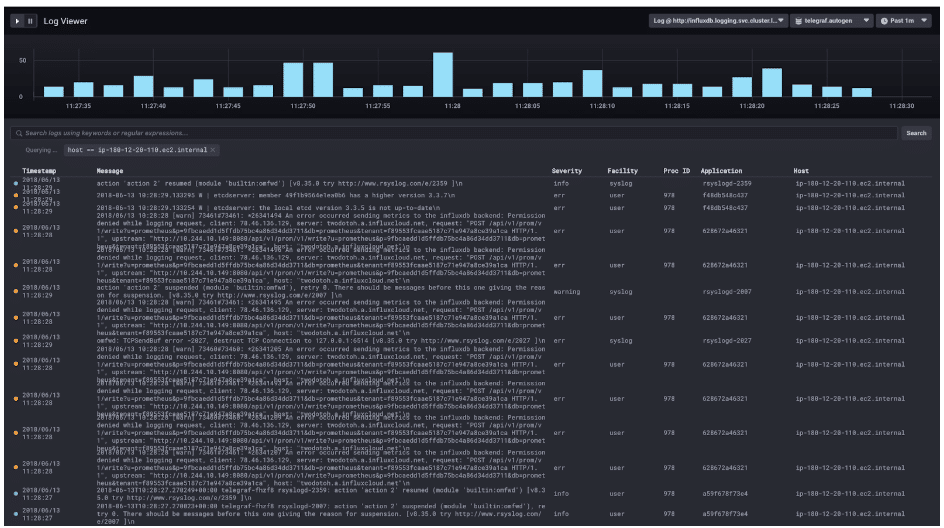
For those of you who need help finding it, look for the “log” icon in the left-hand navigation panel. It’s actually hard to miss!

Where We Go from Here
The Log Viewer is currently bound to the syslog measurement which is created by the new Telegraf syslog plug-in. However, as we continue development on the log viewer, we plan to add additional configuration options including the ability to change the position, order and visibility of the various columns – just like the table control. We also plan to provide the ability to add visualization of additional tags, if you’ve extended the Telegraf plug-in to provide additional contextual data to help with your analysis of the events captured within the log events themselves. We also want to make it easy to jump between dashboards and the Log Viewer, and possibly make an embeddable log viewer graph type for dashboards – saving additional time and effort.
Before you head off to explore all the new capabilities in Telegraf and Chronograf, it’s important to point out some anti-patterns and problems that we aren’t planning on addressing. For starters, InfluxDB isn’t intending to be a log archive. If you need longer-term storage of logs for purposes of compliance or archival, there are more cost-effective solutions for this out of the 50+ log management tools. It is best to align the retention policy of your log data with the primary window across which you plan to perform real-time operational triage and drill-down. You can, of course, extract and derive metrics (counts by the various metadata tags: host, severity, etc.) from the log data itself – and effectively downsample that information while eliminating the messages themselves. This would create a historical baseline for that metrics first approach and allow for an early warning if your counts start to exceed those historical norms.
If you are looking for more advanced analysis use cases – think SIEM style activities such as user and entity behavior analytics or security orchestration and automated response based on the event data – this isn’t something from an “out-of-the-box” user interface perspective that we plan to address. Typically these use cases require longer-duration log archival along with more sophisticated machine learning algorithms running across the entire data set.
As we continue to simplify and ease the overall experience, there are likely to be additional analysis functions added. For example, if your log events include Correlation IDs, we could calculate the time between events and plot them on a histogram. There is much more to do here, but we have just begun to drive home the ability for you to take a metrics first approach to viewing, exploring, and analyzing the supporting log events. We are attempting to improve the overall observability of your systems, applications, and sensors while also enabling faster problem resolution. Let us hear your thoughts over at the community site.
