How to Fix Common Errors for Beginners in InfluxDB Cloud 2.0
By
Anais Dotis-Georgiou
updated December 14, 2025
Use Cases
Product
Developer
Navigate to:
In this post, we’ll review some common InfluxDB Cloud 2.0 errors for beginners. We’ll discuss probable causes as well as recommended fixes. This blog uses the Telegraf System Configuration and data as an example to illustrate the various errors you may encounter. Having some familiarity with this dataset is useful in understanding the issue and the resolution. However, you may run into these issues with your own time series data, and hopefully, these examples highlight how you can address them!
Error 1: specified column does not exist in table: _time
Possible causes: A likely cause of this error is using an aggregator Flux function. Many aggregators – including count(), mean(), and median() – drop the _time column because they combine rows. So for example, the following Flux query:
from(bucket: "System")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu" and r["_field"] == "usage_system")
|> limit(n: 10)
|> count()Produces the following output:
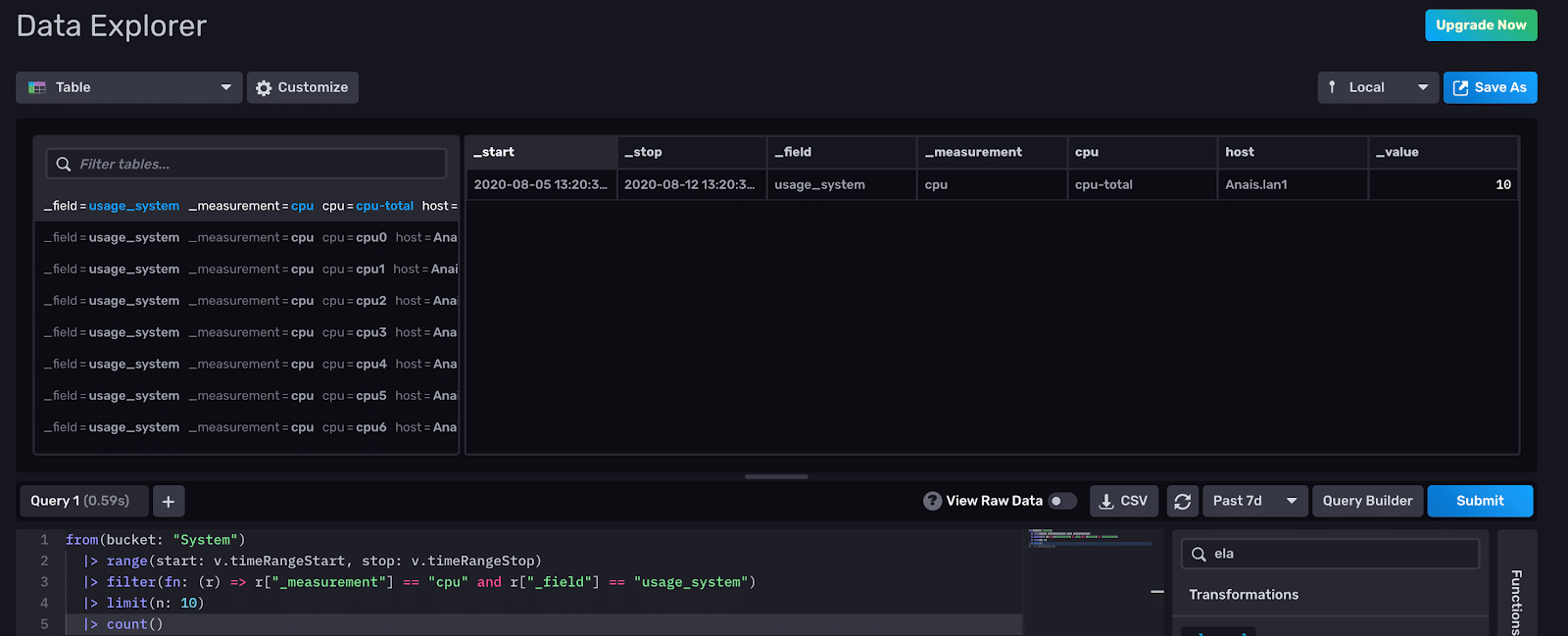
Now if I try to add a function to my Flux script that operates on the _time column, I will get the error above. For example, this query will yield our error:
from(bucket: "System")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu" and r["_field"] == "usage_system")
|> limit(n: 10)
|> count()
|> elapsed(1s)As we can see from the screenshot above, our Flux query output doesn’t have a _time column because count() calculates the sum of values across all timestamps. The elapsed() function returns the time between subsequent records in the _time column. The _time column has been dropped after the application of count(), so we receive the error above.
Also, please be careful when using drop() or keep() functions. For example, make sure to include the _time as an input parameter when using the keep() function.
Recommended fix: First, I recommend switching between your visualization and the Raw Data view or table view when debugging Flux. Practicing this habit will allow you to keep track of what columns have been kept or dropped after each data transformation. Second, when using aggregate functions like count(), mean(), and median(), try using aggregateWindow() instead of the raw function as it preserves the _time column:
from(bucket: "System")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu" and r["_field"] == "usage_system")
|> limit(n: 10)
|> aggregateWindow(every: v.windowPeriod, fn: count)
|> elapsed(unit: 1s)
Error 2: unsupported aggregate column type string
Possible causes: If you are trying to use an aggregator, like mean(), on a column containing string types, you will get this error. This likely means that numerical data was fed into the platform as a quoted string.
Recommended fix: You may want to consider going back to the data collection point and modifying the configuration so that the data is fed in as the appropriate numerical type. But, in some cases, this simply isn’t possible. So, you can convert strings to numerical values with one of the following type-conversion functions first: int() or float().
For example, your Flux script might look like this:
from(bucket: "bucket-name")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "measurement-name" and r["tag-key-name"] == "tag-value-name")
|> map(fn:(r) => ({ r with tag-key-name-as-int: int(v: r.tag-key-name) }))
|> mean(column: "tag-key-name")Error 3: failed to initialize execute state: could not find bucket "bucket-name"
Possible causes: When you create a bucket in the UI, you might have accidentally included a whitespace. For example, your bucket name might be “bucket-name “. If you go directly to the Flux Script Editor, and run:
from(bucket:"bucket-name")
You’ll get that error. This issue #19399 has been created in response.
Recommended fix: First, use the Flux Query Builder to a) search for your bucket and b) select your bucket to verify that your bucket exists.

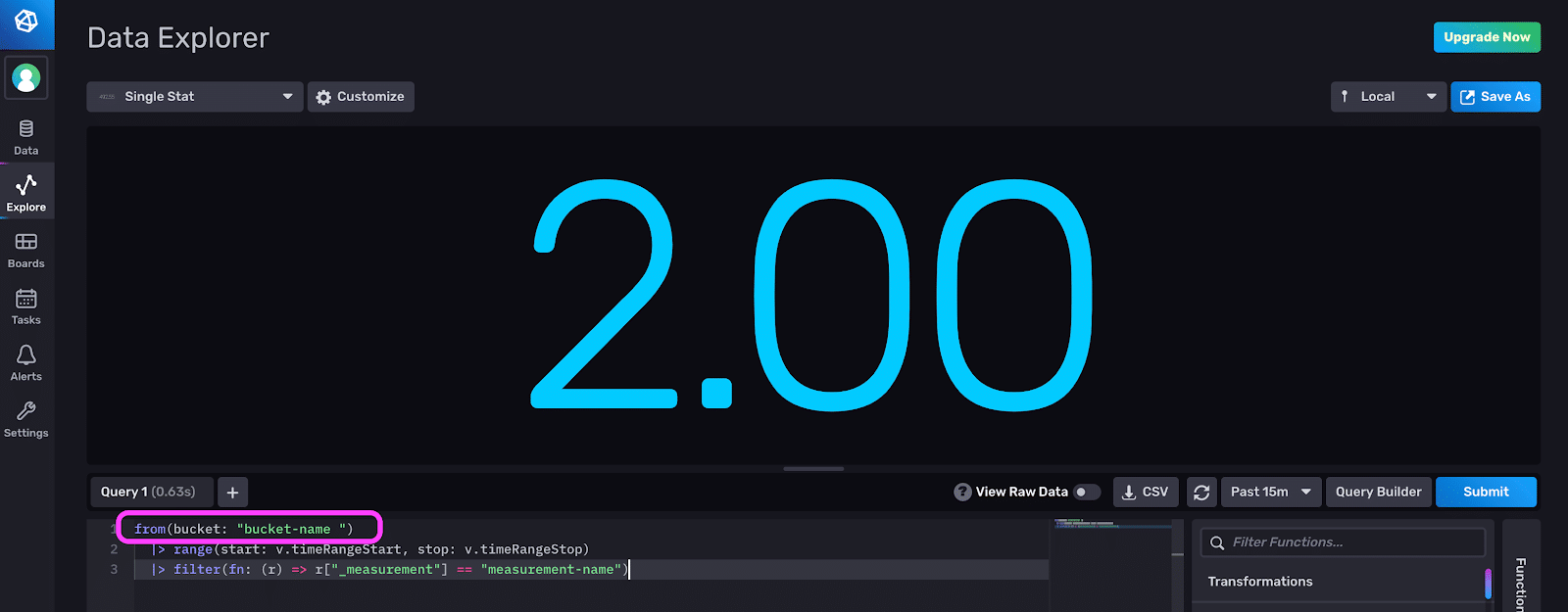
Second, switch over to the Flux Script Editor to determine whether you have trailing white spaces in your bucket-name. Here we see that our bucket name does in fact contain a trailing white space.
I hope you find this blog useful if you run into any of these errors with InfluxDB Cloud 2.0. If you have any questions, please post them on the community site or tweet us @InfluxDB. Thanks!
