Getting Started: Writing Data to InfluxDB
By
Anais Dotis-Georgiou /
Product, Use Cases, Developer
Aug 09, 2020
Navigate to:
This is a beginner’s tutorial for how to write static data in batches to InfluxDB 2.0 using these three methods:
- Uploading data via the InfluxDB UI
- Importing directly into InfluxDB
- Using Telegraf and the Tail plugin
Before beginning, make sure you’ve either installed InfluxDB OSS or have registered for a free InfluxDB Cloud account. Registering for an InfluxDB Cloud account is the fastest way to get started using InfluxDB.
The dataset
For the purposes of this tutorial, I used Bitcoin Historical Data, “BTC.csv” (33 MB), from kaggle from 2016-12-31 to 2018-06-17 with minute precision in Unix time (~760,000 points). The data looks like this:
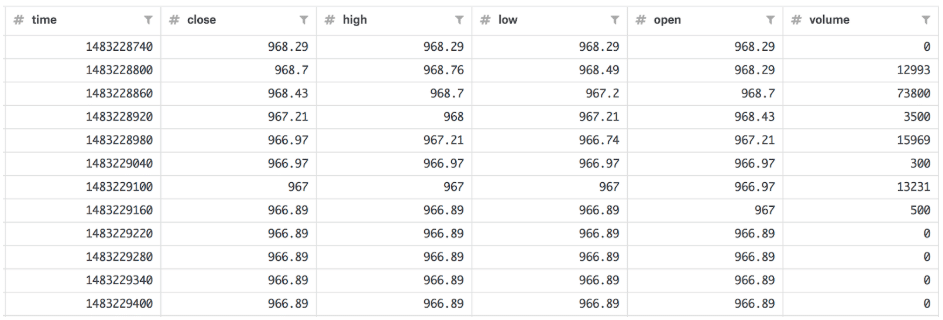
I also converted the timestamp to nanosecond precision.
1. Uploading via Chronograf
Chronograf has two requirements for uploading data. The file size must be no bigger than 25MB and written in line protocol, the data ingest format for InfluxDB. I converted the data to line protocol in myLineProtocolData.txt. To convert “BTC.csv”, the csv containing the data above, to line protocol, I used the following script, csv_to_line.py:
import pandas as pd
#convert csv to line protocol;
#convert sample data to line protocol (with nanosecond precision)
df = pd.read_csv("data/BTC_sm_ns.csv")
lines = ["price"
+ ",type=BTC"
+ " "
+ "close=" + str(df["close"][d]) + ","
+ "high=" + str(df["high"][d]) + ","
+ "low=" + str(df["low"][d]) + ","
+ "open=" + str(df["open"][d]) + ","
+ "volume=" + str(df["volume"][d])
+ " " + str(df["time"][d]) for d in range(len(df))]
thefile = open('data/chronograf.txt', 'w')
for item in lines:
thefile.write("%s\n" % item)After this conversion, myLineProtocolData.txt looks like:

Next, navigate to http://localhost:9999/ or your InfluxDB Cloud url, which varies depending on your region, and login. My InfluxDB Cloud url is https://us-west-2-1.aws.cloud2.influxdata.com, for example.
Once we’ve logged into InfluxDB v2, we can now write our line protocol data to a bucket InfluxDB with the UI. We’ll click on the Data tab on the left of the landing page:
The Data tab allows us to create buckets, create Telegraf configurations, create tokens and initialize Client Libraries. Click the “Create Bucket” button to create a destination bucket for our BTC data.
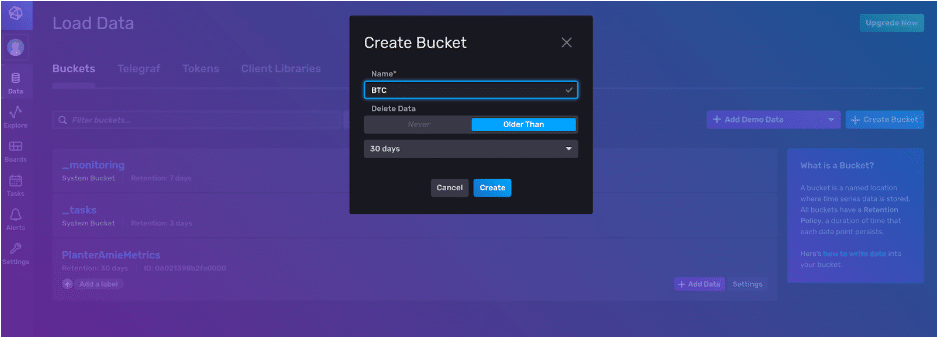
Now, we create a bucket, give it the name “BTC” and set a retention policy. Our data will automatically be deleted when it’s older than 30 days.
Now we can write our line protocol to our BTC bucket. We click the + Add Data button and select the method we want to write data to our corresponding bucket.
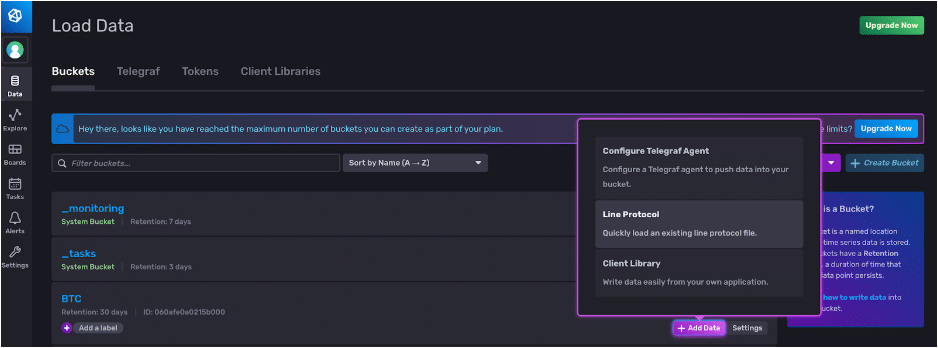
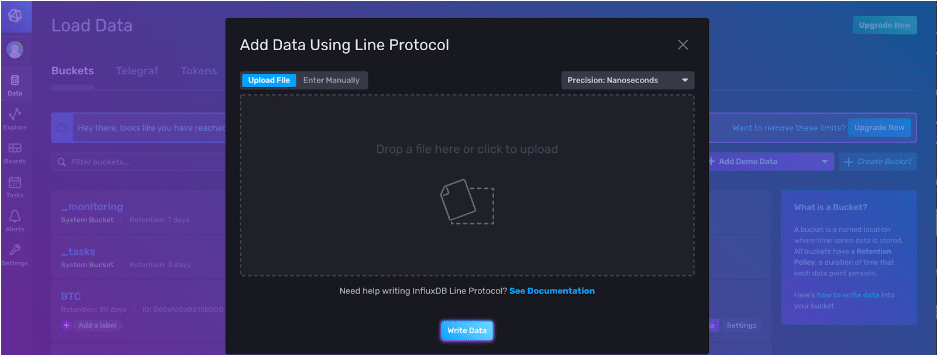
We can copy and paste our line protocol and specify the precision that we want to write our point to.
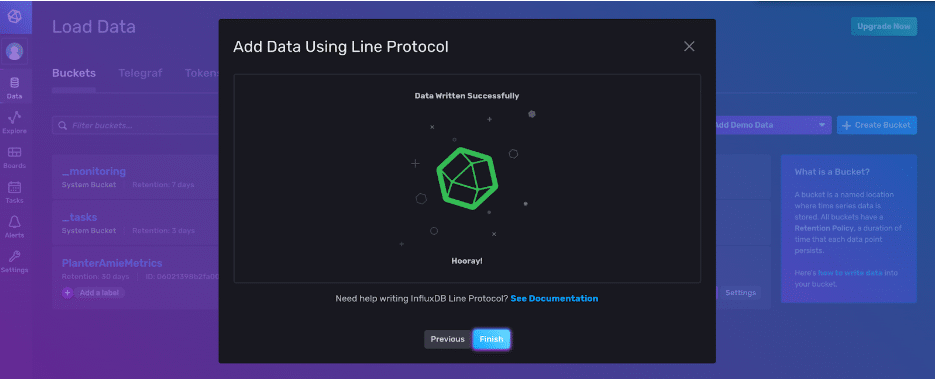
Click the Write Data button to finish. Congratulations! You’ve written a point to InfluxDB v2.
2. Importing directly into InfluxDB 2.0 OSS
If your data size is larger than 25 MB and you’re using InfluxDB 2.0 OSS, I recommend using this method to write data directly into InfluxDB v2. Use the following CLI command:
influx write \
-b bucketName \
-o orgName \
-p ns \
--format=lp
-f /path/to/myLineProtocolData.txtAll you need to use influx write is to specify your bucket name -b, your org name -o, and your timestamp precision -o, the format of your file. In our example, our file is in line protocol or --format=lp, and the path to your file.
3. Using Telegraf and the Tail plugin for InfluxDB OSS and InfluxDB Cloud
The Tail Plugin is really meant to read streaming data. For example, you could make continuous requests to an API, append your new data to your myLineProtocolData.txt file, and Telegraf with the Tail plugin will write the new points. However, you can change the read settings in the configuration file (conf) for the tail input so that you can read a static file. We’ll get into that in a bit.
Next, you will need to create a telegraf.conf file. If you have Telegraf installed locally, you can run this CLI cmd to generate a Telegraf config with the appropriate input and output filters:
telegraf --input-filter tail --output-filter influxdb_v2 config > telegraf.confFeel free to name your conf something more descriptive too, like tail.conf, so you can remember what plugins you included in your conf later on.
If you don’t have Telegraf installed locally, you can search for the right configs here, and copy and paste the configs manually into the UI.
Make these changes to the config file:
- Specify the precision of your data (line 64). For this example, our BTC data has been converted to ns precision, so:
precision = "ns" - Since we're not performing a monitoring task, we don't care about setting a 'host' tag. Set
omit_hostname = trueso that Telegraf doesn't set a 'host' tag (line 93). - Navigate to the OUTPUT PLUGIN section.
- Specify your InfluxDB instance(line 111):
urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"] # required - Specify your bucket, token, and organization (line 113-120)
- Navigate to the SERVICES INPUT PLUGIN section.
- Specify the absolute path for your line protocol txt file (line 544)
- Normally (with the Tail plugin), Telegraf doesn't start writing to InfluxDB unless data has been appended to your .txt file because the Tail plugin's primary purpose is to write streaming data to InfluxDB. This is determined by the from_beginning configuration which is normally set to false, so that you don't write duplicate points. Since our data is static, change this configuration to true (line 546):
from_beginning = true
- Specify the method of data digestion (last line):
data_format = "influx"
To use this Telegraf config in InfluxDB v2, follow the following documentation on how to manually configure Telegraf with the UI. Essentially, you just need to copy and paste your config into the right place.
I hope this tutorial helps get you started using Telegraf. If you have any questions, please post them on the community site or tweet us @InfluxDB. Thanks!
Now that you’ve read this tutorial (Part One of our Getting Started series), make sure you read Part Two, “Getting Started: Streaming Data into InfluxDB”.
