Extending InfluxDB with Serverless Functions
By
Nate Isley
Product
Use Cases
Developer
Company
Jun 04, 2020
Navigate to:
Data ingestion and data analysis are the yin and yang of a time series platform. There are many resources to help you ingest data. Typical ingestions are agent-based, imports via CSVs, using client libraries, or via third-party technologies. Once your time series data arrives, analysis completes the circle and often leads to additional data collection, and so on and so forth.
Native InfluxDB tools such as Tasks, Dashboards, and Flux typically provide the needed insight within the platform, but some use cases necessitate extending the platform. For those, InfluxDB’s unified API provides a complete set of integration endpoints. This extensibility is one of the things developers love about InfluxDB.
To illustrate, I’ve provided two simple examples implemented on Amazon Web Services’ (AWS) functions as a service offering - Lambda. Serverless functions such as Lambda are useful for almost any architecture because they are decoupled units of work that are relatively easy to connect.
The setup
My example incorporates a Flux Task that synthetically monitors the response time of a web application. InfluxDB gathers the data and acts as the backend analytics engine that the service processor uses to power its business processes.
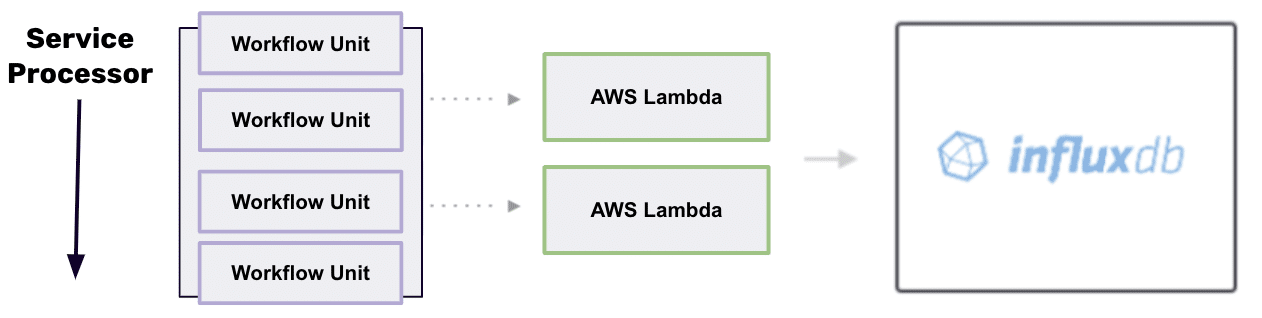
I replicated the synthetic monitoring Task three times with different URLs and stored the results in a bucket with the name of the monitored company. For example, one of my tasks monitors Uber’s response time, and the response time is stored in a bucket called “Uber”. The end result? Three InfluxDB tasks capturing website performance in a uniform data set differentiated only by bucket name.
Using AWS Lambda to query InfluxDB
The first decision when creating a Lambda is to pick which language to use. To make it easier to walk through development, I used NodeJS. AWS’ NodeJS Integrated Development Environment support means the first example can be created entirely within the browser.
To follow along, sign up for a free AWS account and complete Lambda’s getting started steps. Create a hello world NodeJS Lambda and copy/paste Example 1 into the console. On the InfluxDB side, sign up for a free InfluxDB Cloud account, create the Flux task, and grab your org-id and token to insert into Example 1’s code:
var https = require('https');
exports.handler = function(event, context) {
var queryForCount = "from(bucket: \"Pingpire\") |> range(start: -1h) |> filter(fn: (r) => r[\"_measurement\"] == \"PingService\") |> filter(fn: (r) => r[\"_field\"] == \"response_time_ms\") |> filter(fn: (r) => r[\"method\"] == \"GET\") |> count()"
// An object of options to indicate where to post
var post_options = {
host: 'us-west-2-1.aws.cloud2.influxdata.com',
path: '/api/v2/query?orgID=<your-ord-id>',
method: 'POST',
headers: {
'Content-Type': 'application/vnd.flux',
'Authorization': 'Token <your-user-token>'
}
};
// Set up the request
var post_req_uber = https.request(post_options, function(res) {
res.on('data', function(chunk) {
console.log('Response: ' + chunk);
context.succeed();
});
res.on('error', function(e) {
console.log("Got error: " + e.message);
context.done(null, 'FAILURE');
});
});
// post the data
post_req_uber.write(queryForCount);
post_req_uber.end();
}Here is a screenshot of the AWS IDE output when I tested the Lambda in my browser:

This first example is a straightforward use of a NodeJS HTTPS POST request to demonstrate direct use of InfluxDB’s API. Using the API is powerful and simple, but many developers would rather use libraries instead of making HTTP calls. My second example invokes InfluxDB via an InfluxDB client library to illustrate this approach.
Setting up the second example takes a little more work as the base AWS NodeJS library is limited. To proceed, you will need the AWS command-line interface (CLI) to add node packages - follow installing/using the AWS CLI.
Once you have the CLI, update the available library/packages for your lambda function with
>npm install @influxdata/influxdb-clientin a local directory. You can zip that directory and use the CLI to import it to an AWS Lambda directly, or do what I did and use the NodeJS IDE’s “upload a zipfile” option under code entry type.
Once the Lambda has the integrated InfluxDB client library, copy/paste Example 2’s’ code:
const { InfluxDB } = require('@influxdata/influxdb-client')
const token = '<your-user-token>'
const org = '<your-org-id'
const client = new InfluxDB({ url: 'https://us-west-2-1.aws.cloud2.influxdata.com', token: token })
const queryApi = client.getQueryApi(org)
exports.handler = function(event, context, callback) {
var customerJSON = JSON.parse(JSON.stringify(event));
var customers = [];
var x;
for (x in customerJSON) {
customers.push(customerJSON[x]);
}
var y = 0;
for (var i = 0; i < customers.length; i++) {
var query = `from(bucket: "${customers[i]}" ) |> range(start: -10m) |> filter(fn: (r) => r.method == "GET" ) |> count(column: "_value")`;
console.log(query)
queryApi.queryRows(query, {
next(row, tableMeta) {
const o = tableMeta.toObject(row);
console.log(`Customer "${customers[y++]}" consumed ` + o._value + ` pings.`);
},
error(error) {
console.error(error)
console.log('\nFinished ERROR')
},
complete() {
console.log('\nFinished SUCCESS')
},
})
}
}As you can see, using the client library is not drastically different from API access. You still need the token, org-id, and query, but native libraries almost always make developers more efficient.
To execute and test this example, recall that my InfluxDB has several tasks for monitoring company websites, and the results are differentiated by bucket name. My Lambda takes in a JSON list of companies and loops over the list to query InfluxDB for results. Here is my test JSON:
{
"Company1": "Microsoft",
"Company2": "Uber",
"Company3": "Pingpire"
}Here is a screenshot of the AWS IDE output for the second Lambda:

Exploring serverless integrations continues...
These initial examples demonstrate the ease with which one can get started extending InfluxDB with Lambda. Over the coming weeks, I will be expanding on this foundation to further explore using Serverless with InfluxDB.
As I mentioned, please try out the above examples today by signing up for free InfluxDB Cloud and AWS accounts. As always, if you have questions, feedback, or want to explore these specific examples please reach out in our community forum or via Slack!
