Building a Data Stream for IoT with NiFi and InfluxDB
By
Craig Hobbs
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
Apache NiFi has been a game changer in the world of IoT, allowing you to automate the transformation and flow of data from IoT, and any edge, sensor to just about anywhere you want. In addition to supporting mission-critical data volumes with rigorous security, data provenance and compliance requirements, NiFi provides developers with a drag-and-drop UI for flow-based programming and automatic “real-time” deployment of new flows.
By combining NiFi & InfluxDB, industries can easily make their IoT data streams securely accessible and usable. This solution enables the enterprise to have a single view of data across all facilities providing for proactive maintenance, failure detection, and other business-based outcomes.
The IoT challenge: OPC-based data
For this example, we will look at OPC data from factory automation and process manufacturing. OPC gives production and business applications across the manufacturing enterprise access to real-time plant-floor information in a consistent manner. However, a common challenge with our enterprise clients is how to connect their facility or enterprise historians with a modern toolset and analytics pipeline while also guaranteeing continuous data flow between them.
Here’s where the NiFi & InfluxDB platform combination can provide a powerful solution in a matter of minutes to securely collect, observe and act on your facility data.
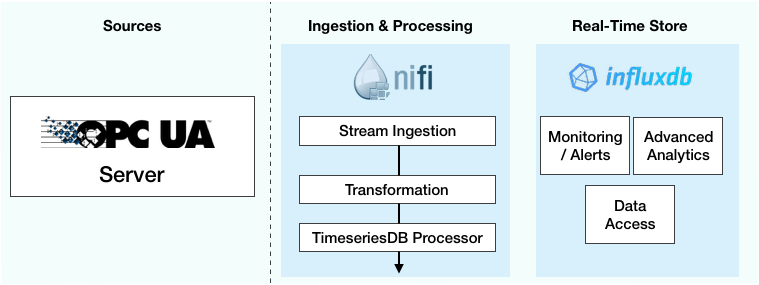
Get started with the NiFi-OPCUA-bundle
Begin by downloading the following NiFi Service & Processor bundle from the Tempus IIoT framework for industrial data ingestion and analysis. These processors and the associated controller service allow NiFi access to OPC UA servers in a read-only fashion.
You will find 2 processors in the Tempus bundle, GetOPCNodeList and GetOPCData. GetNodeIds allows access to the tags that are currently in the OPC UA server. GetOPCData takes a list of tags and queries the OPC UA server for the values.
Configuring the GetNodeList processor
Start by adding the GetOPCNodeList processor to the NiFi canvas:
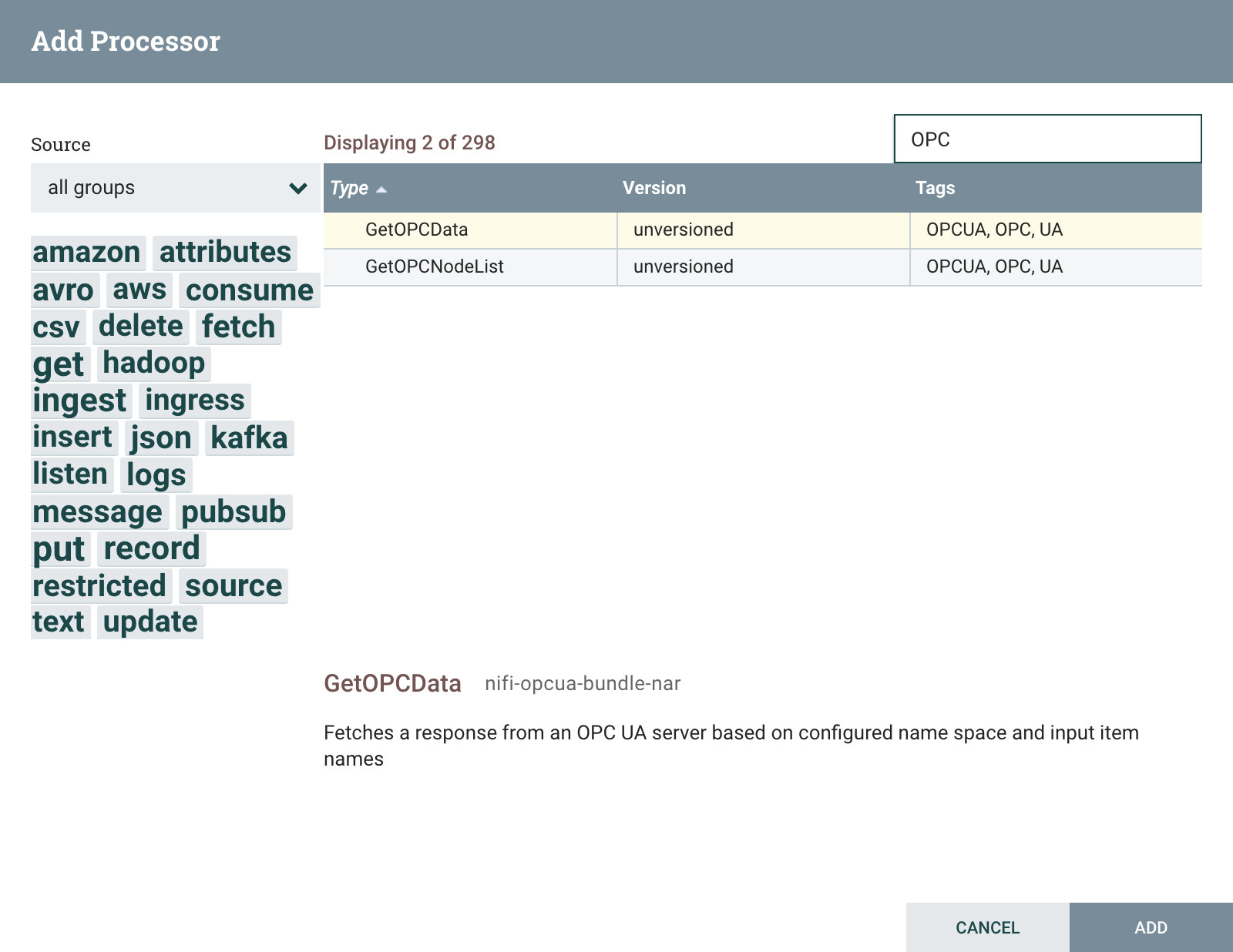
After adding, right click the GetOPCNodeList processor and select Configure. On the PROPERTIES tab select value box for the OPC UA Service Property field and pick Create new service on the following dialog and to add a new instance of the StandardOPCUAService.
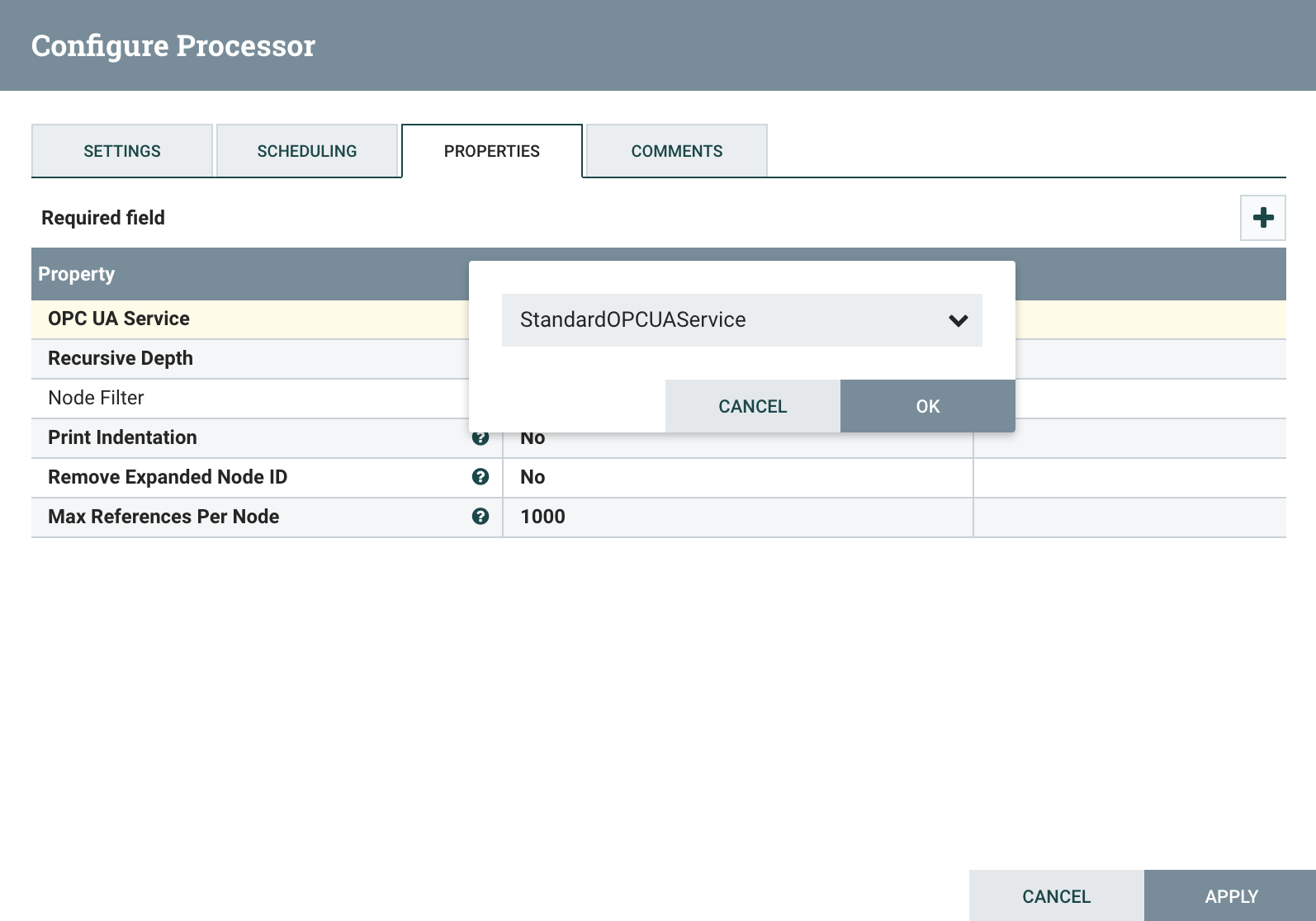
Next, configure the processor filter so it will only return the node-list tag items you’re interested in fetching. Use the Node Filter Property to define a pipe( |
) delimited regular express list of nodes. |
Additionally, you will want to set the Recursive Depth Property for how many branches “deep” the processor will browse into the OPC server’s namespace.
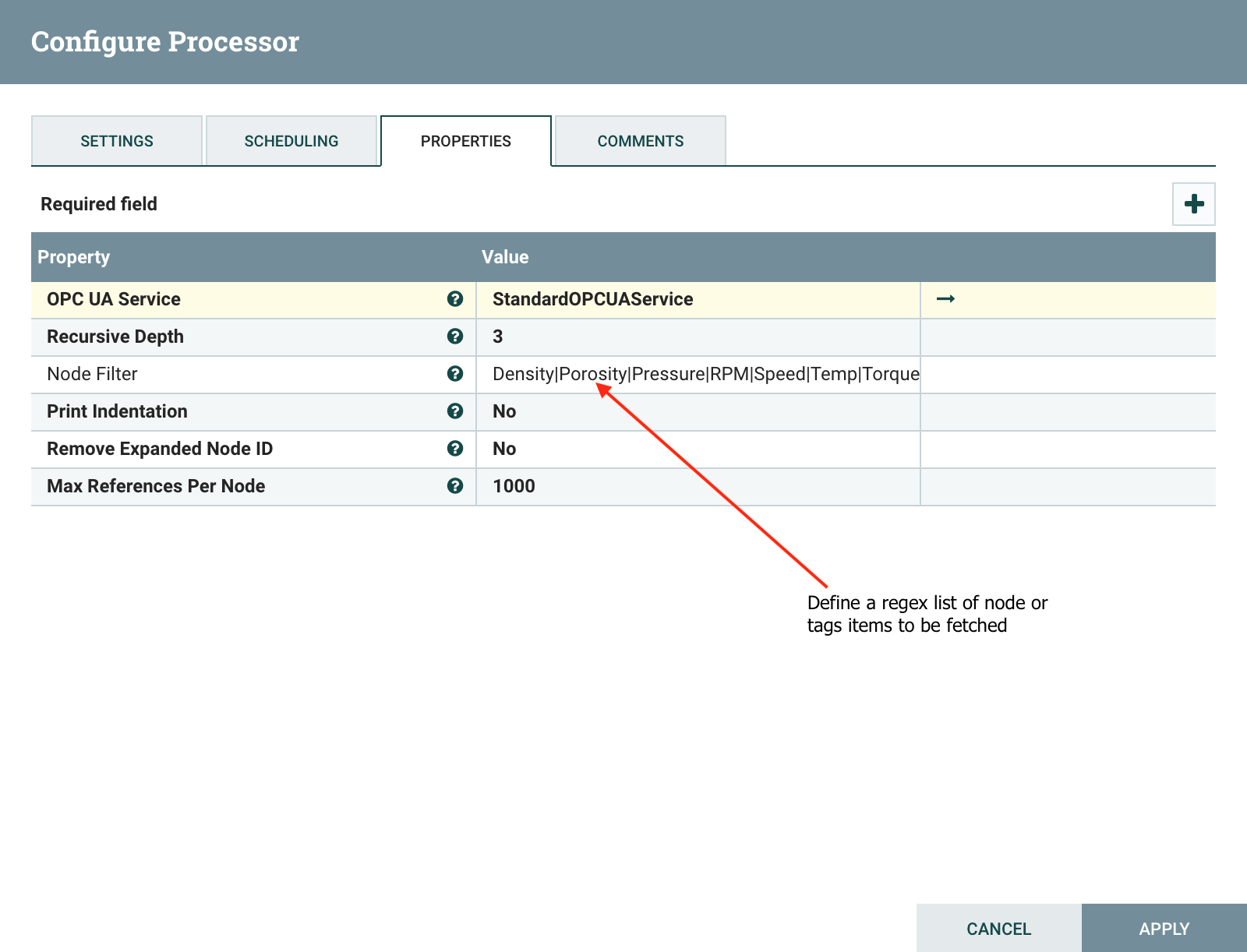
When you are done configuring the processor, click on the edit arrow icon to the right of the controller service. This will take you to the controller service configuration window.
Begin editing the StandardOPCUAService controller by entering the endpoint information of your OPC UA server:
Next, update the security settings handshake mode to match one of the available modes on your OPC-Server:
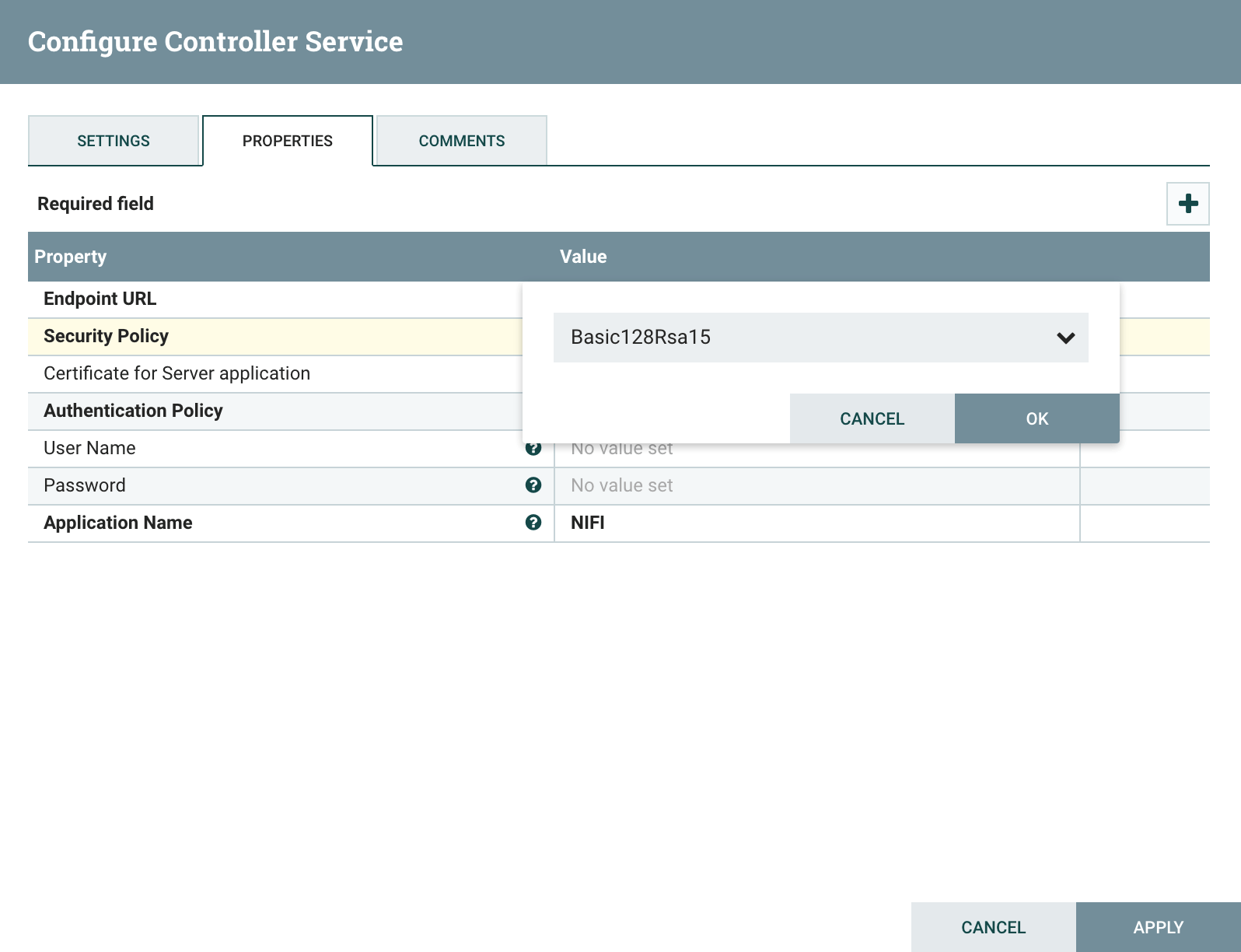
Set the Authentication Policy Property to define how NiFi should authenticate with the UA server. Here, in addition to the Security Policy mode, I’ve added username/password credentials for access.
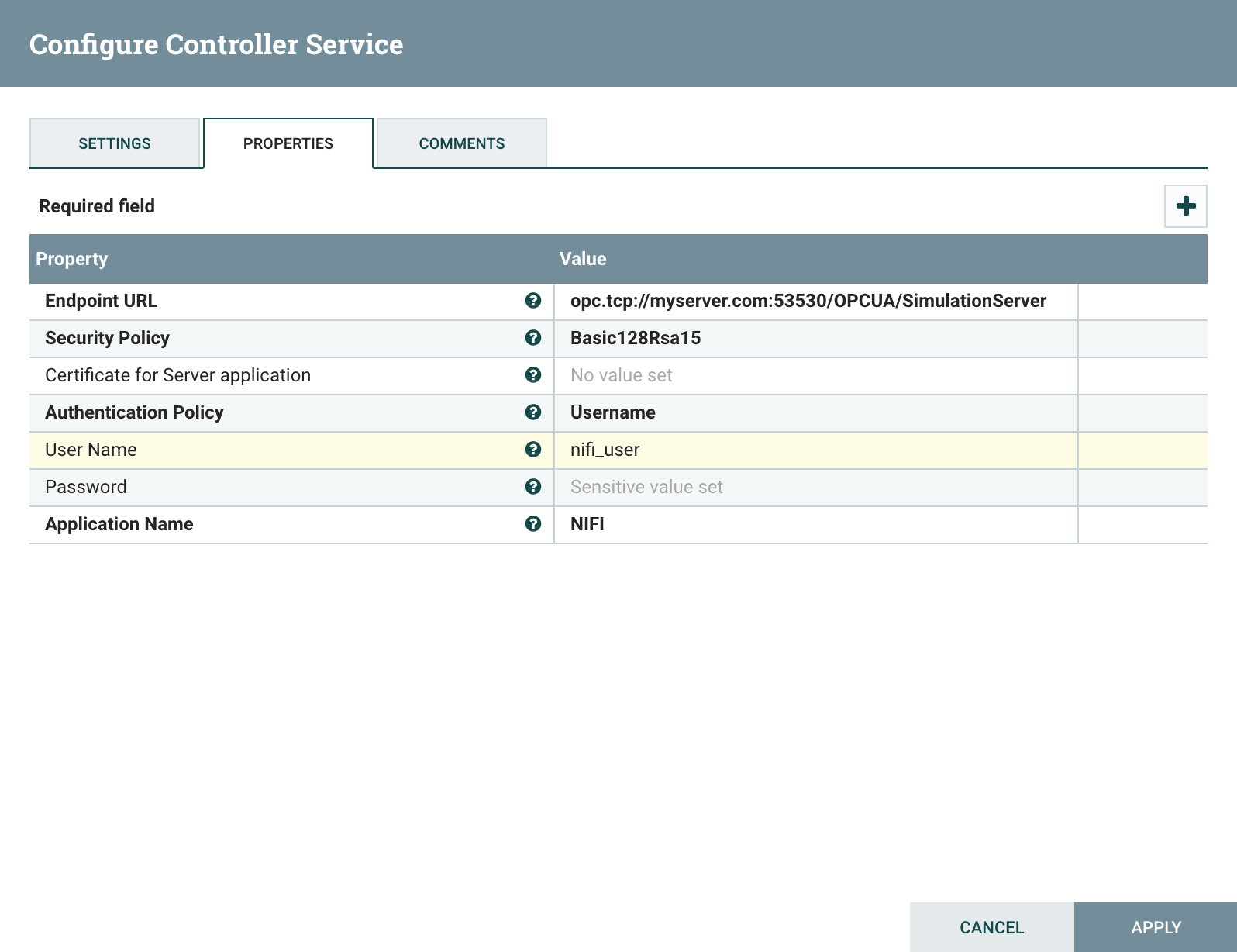
You now have the information needed to access the OPC-Server. Once the configuration of the controller is complete, click apply and enable the controller.
Configuring the GetOPCData processor
Next, add the GetOPCData OPC processor to your NiFi canvas. Right-click on the processor and select Configure from the context menu to configure the processor. Click on the PROPERTIES tab and fill out the information as below.
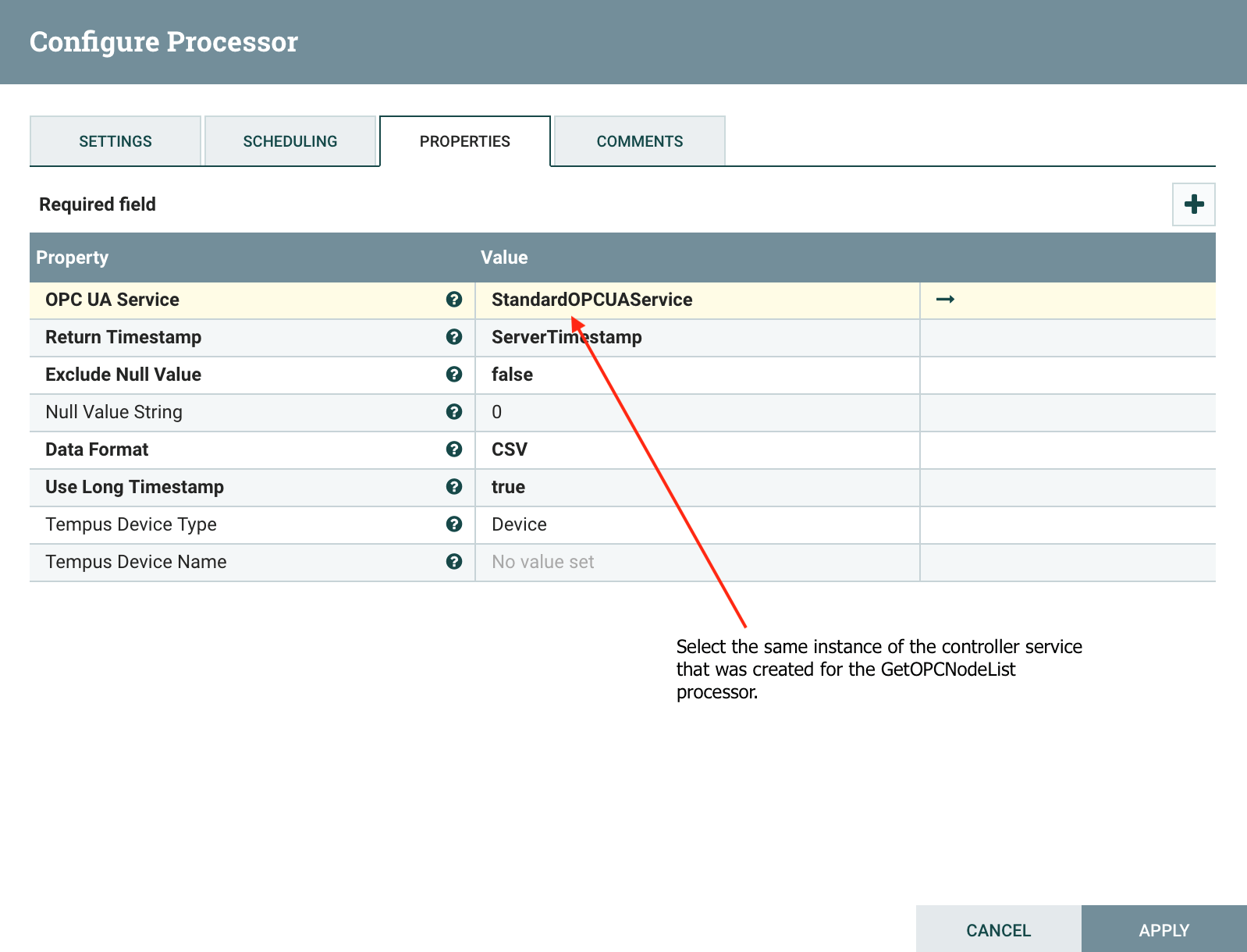
Schema Registry service for record-based flow
The output data from the GetOPCData processor essentially produces CSV style data (minus the header) in the format of tag name, time stamp, value and status.
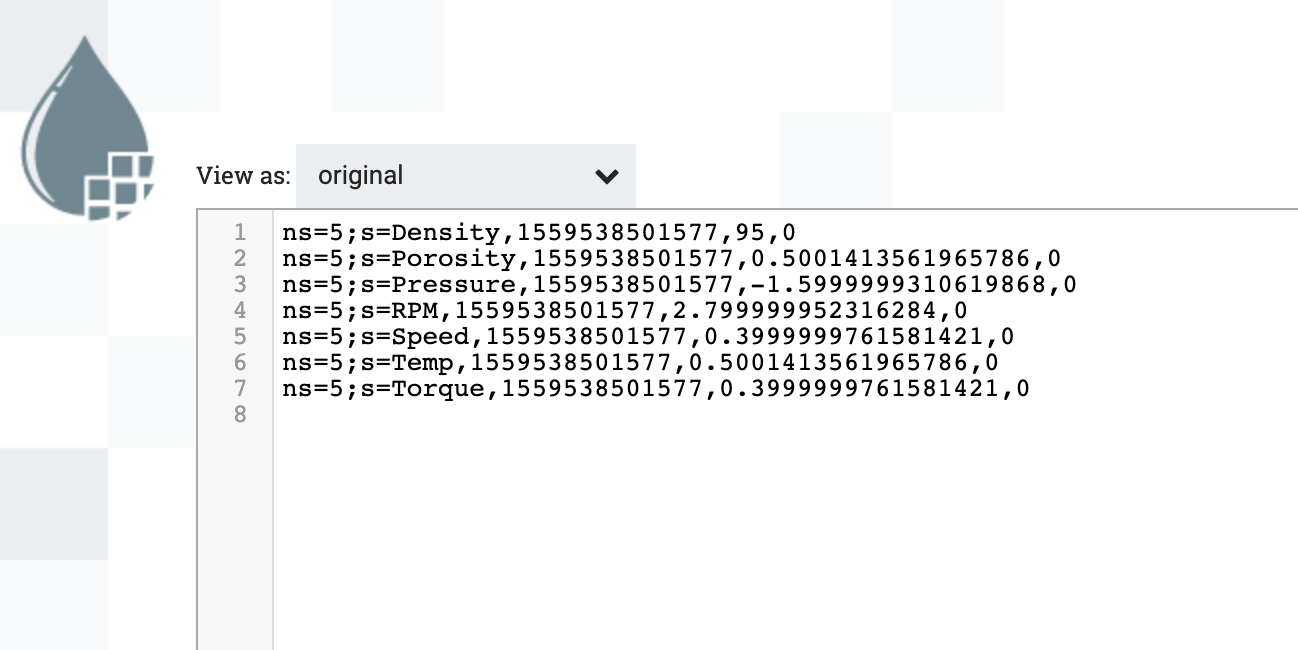
We’ll now add the AvroSchemaRegistry controller service. This tells the record-based processors how to interpret the OPC Tag items.
That service will be added the same way we added the OPCUAClientService?. Click on the edit arrow icon again in the GetOPCData processor to configure.
Next, in the upper righthand corner of the NiFi Flow Configuration screen, click on the plus (+) icon to add a new Controller Service:

Add the AvroSchemaRegistry to the Controller Services. Each property is essentially a name schema pair that the flow can then use to relate a piece of data to a schema.
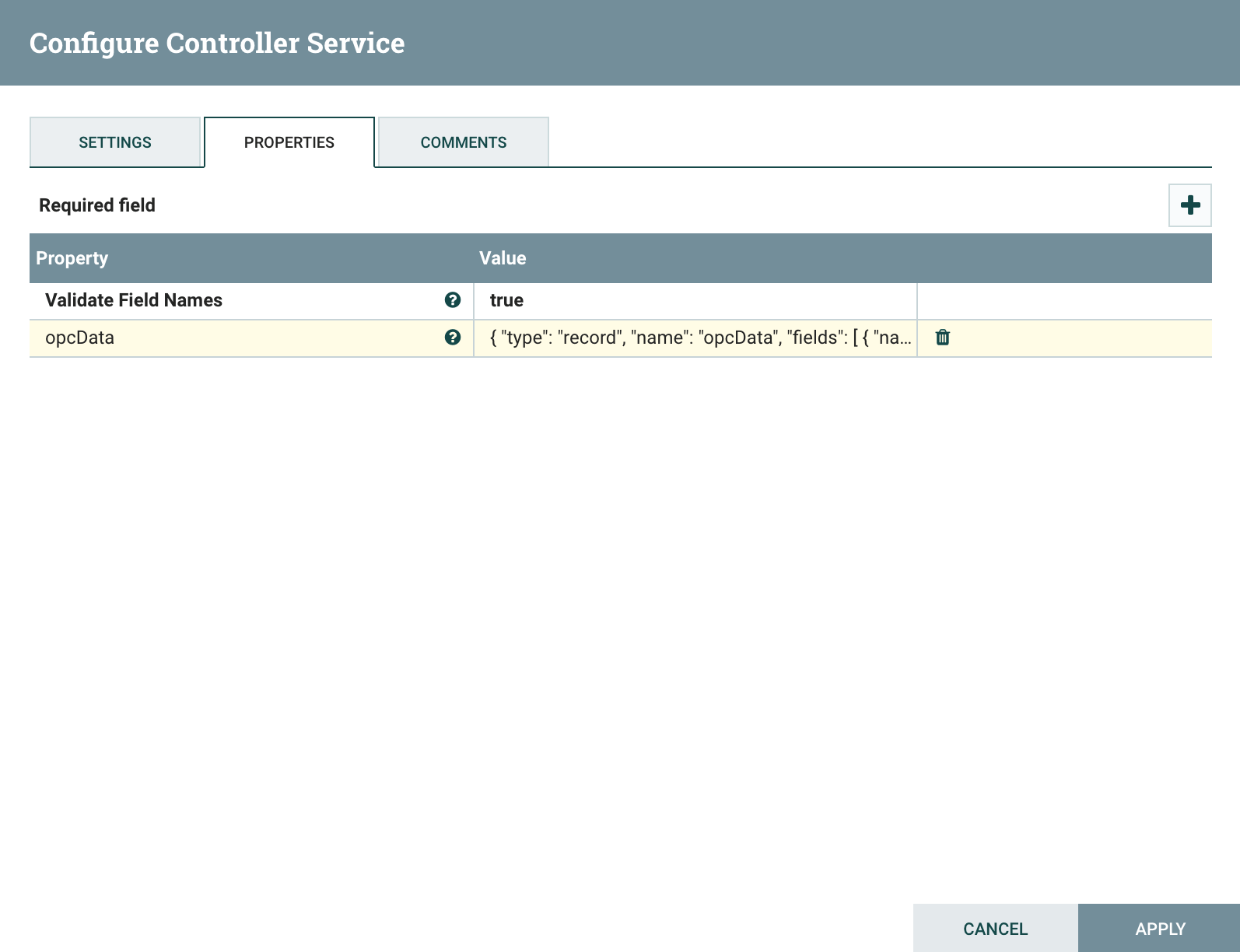
Add the property by clicking the plus icon and naming it opcData, and then copying the avro into the value.
Schema will look like the avro below:
{
"type": "record",
"name": "opcData",
"fields": [
{ "name": "uri", "type": "string" },
{ "name": "ts", "type": "string" },
{ "name": "value", "type": "float" },
{ "name": "status", "type": "int" }
]
}You now have the information needed to access the OPC-Server. Once the configuration of the controller is complete, click apply and enable the controller.
You now have the information needed to use the dynamic avro schema for reading the OPC-Data records. Once the configuration is complete, click apply and enable the controller.
InfluxDB record processor for Apache NiFi
Now it’s time to connect the InfluxDB processor to ingest the OPC data records. To provide the best possible ingest performance, InfluxDB has created a new processor that is based on NiFi Record Design.
Getting started:
Download and install the InfluxDB Processors. Copy the appropriate nar file into the lib directory of your NiFi installation ($NiFi_HOME/lib) and restart NiFi.
https://github.com/influxdata/nifi-influxdb-bundle
Head back to the NiFi canvas and add the PutInfluxDatabasesRecord processor. Connect it to the previous GetOPCData processor:
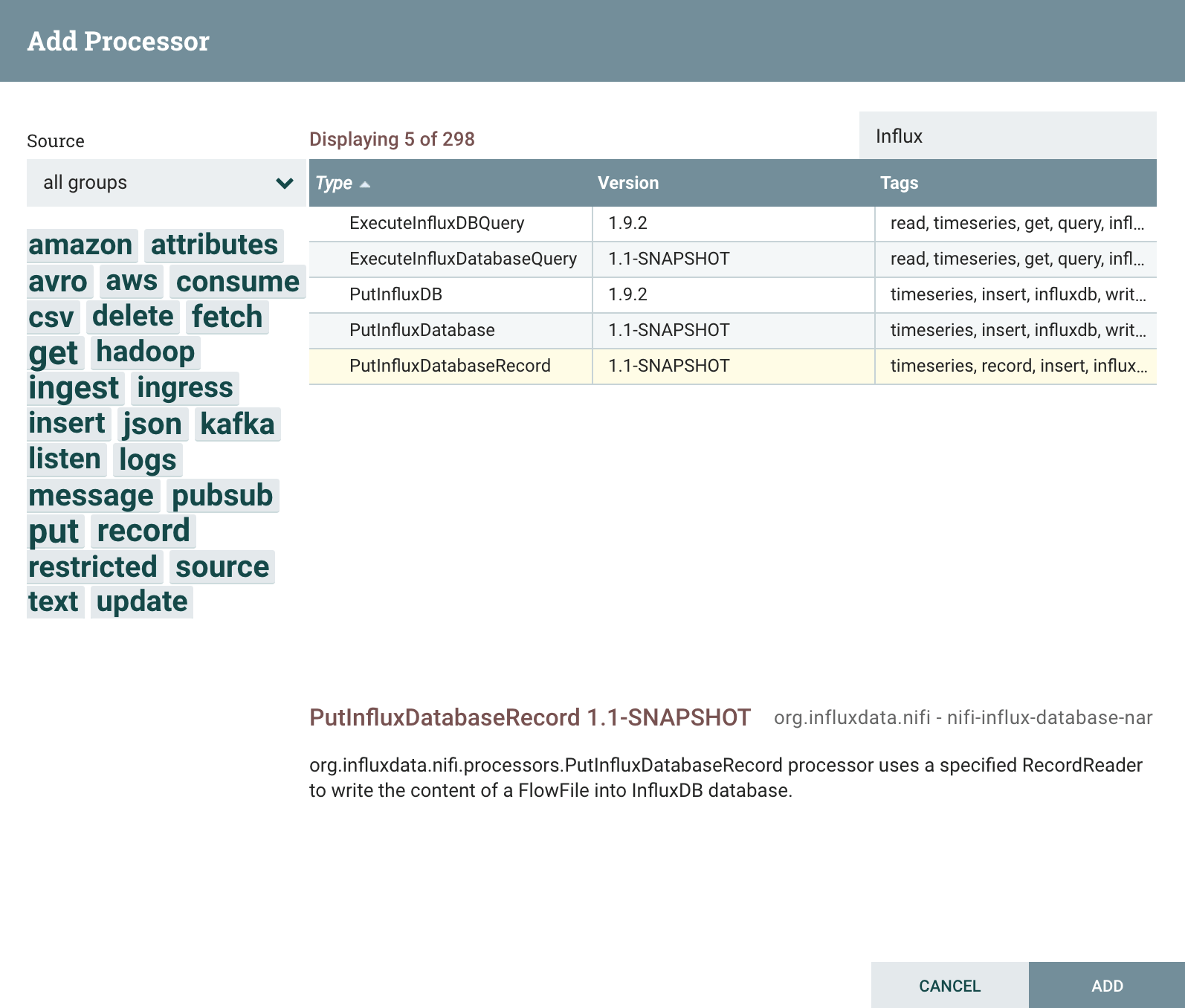
Right click to configure the processor and select the PROPERTIES tab. Start with the Record Reader Property, and select the CSVReader controller service.
After adding, click on the edit arrow icon to configure:
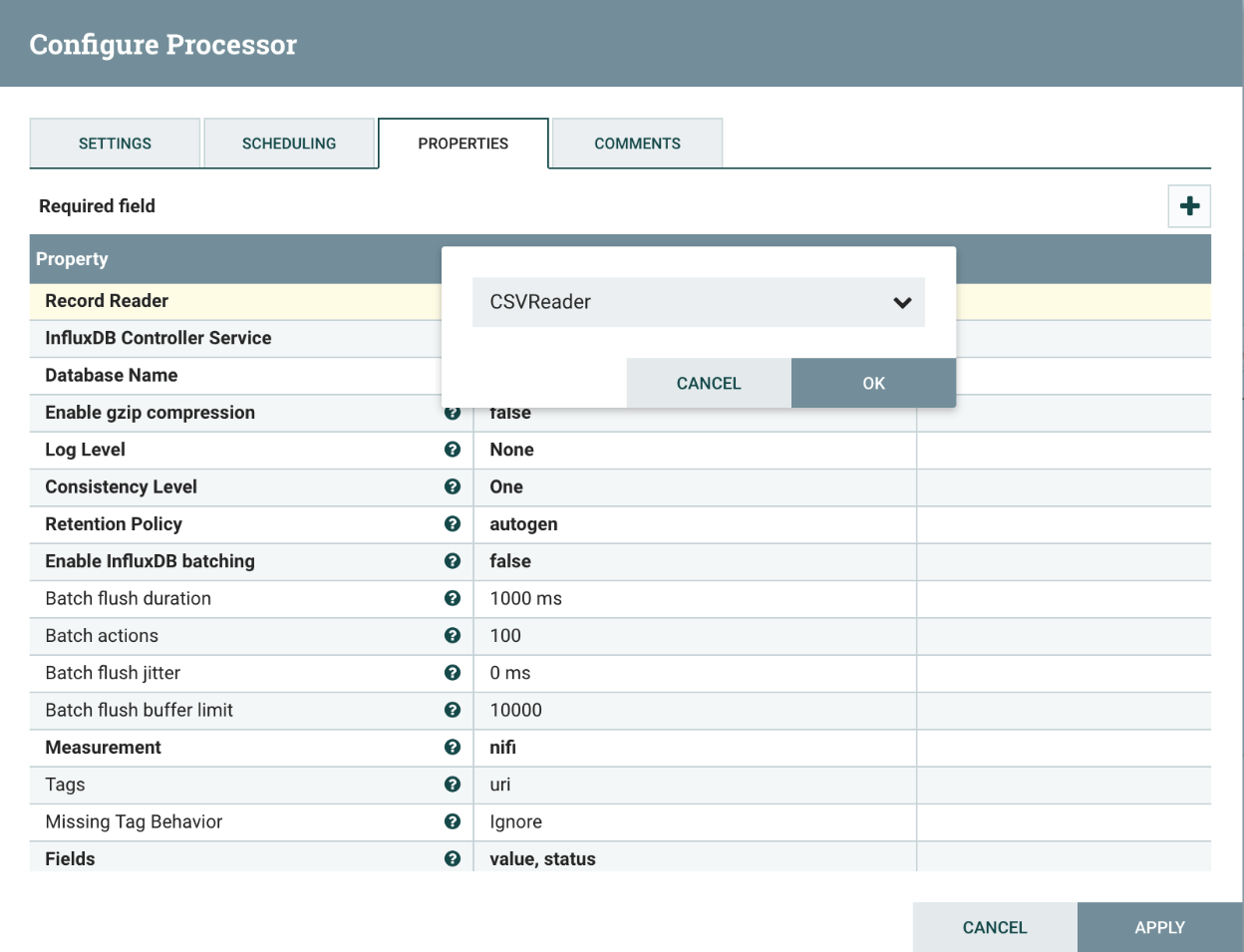
In the controller service properties of the CSVReader, you will set the Schema Access Strategy and Schema Name:
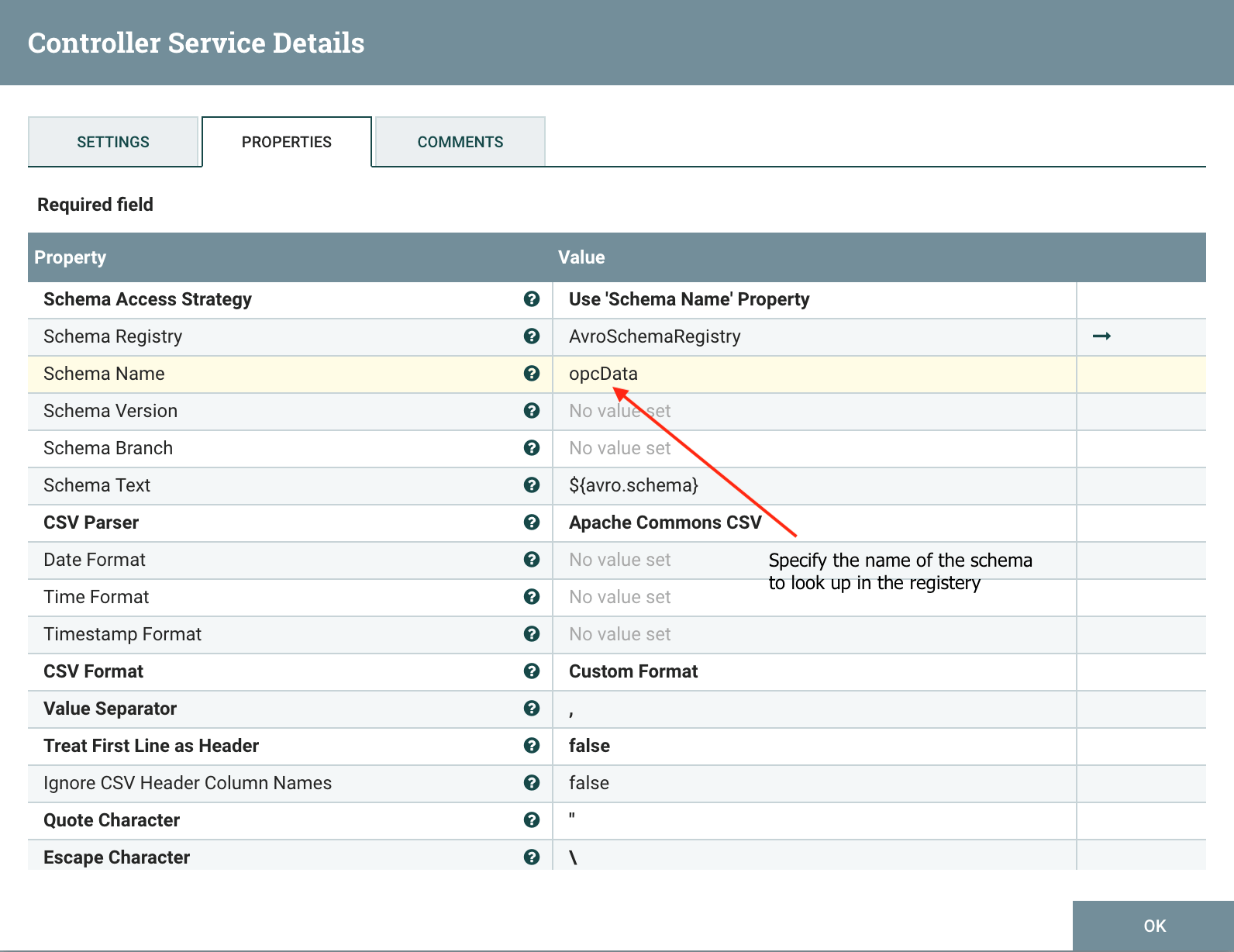
We have previously registered our OPC-Data avro schema with the name opcData. Click apply and enable the controller services.
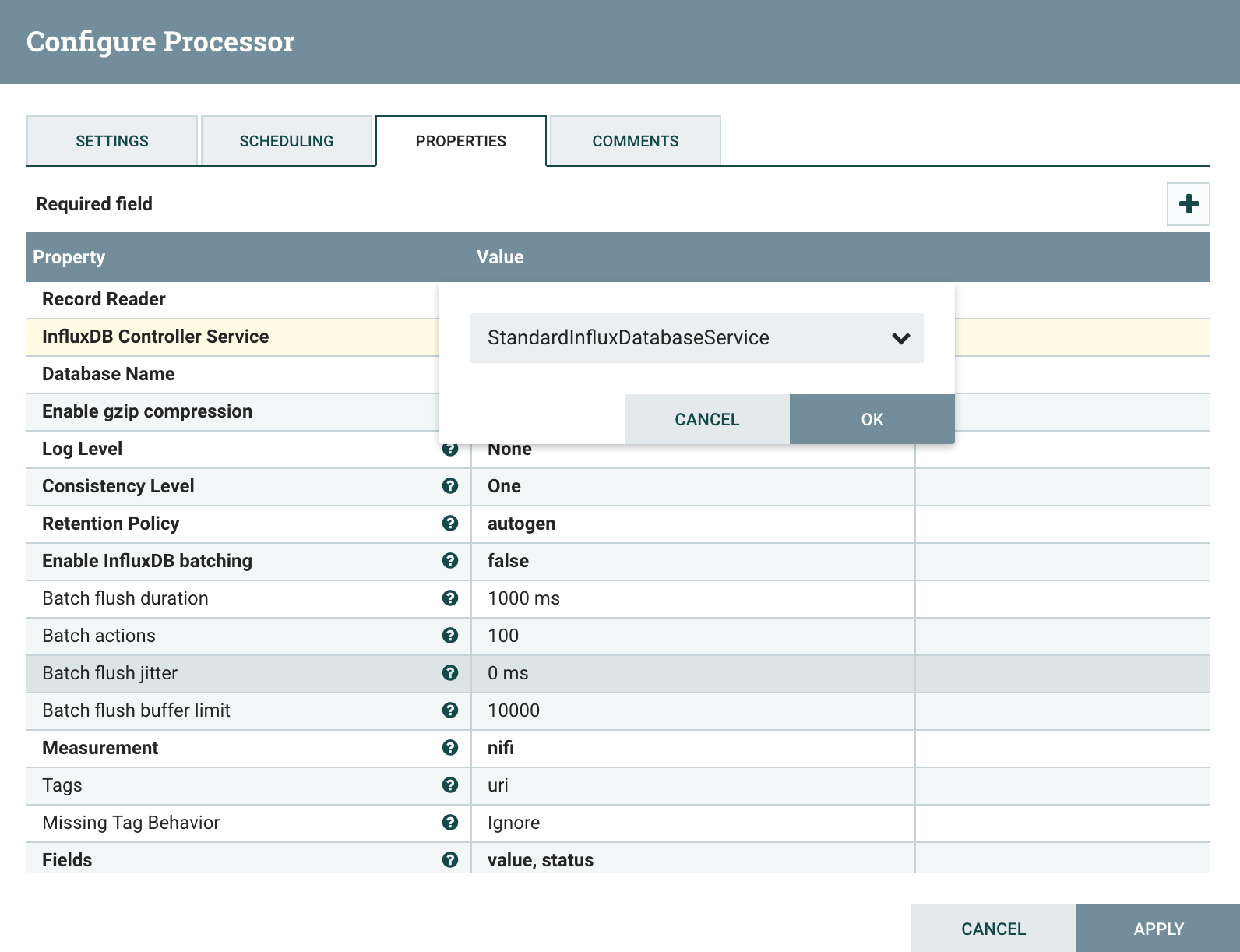
Return to the PutInfluxDatabasesRecord processor and go back to the properties tab. You will want to create a new StandardInfluxDatabaseService to the InfluxDB Controller Service property.
After creating the service, click on the edit arrow icon to configure:
From the service configuration window, define your InfluxDB database, URL and access credentials. This will create a shareable connection service for all NiFi processors:
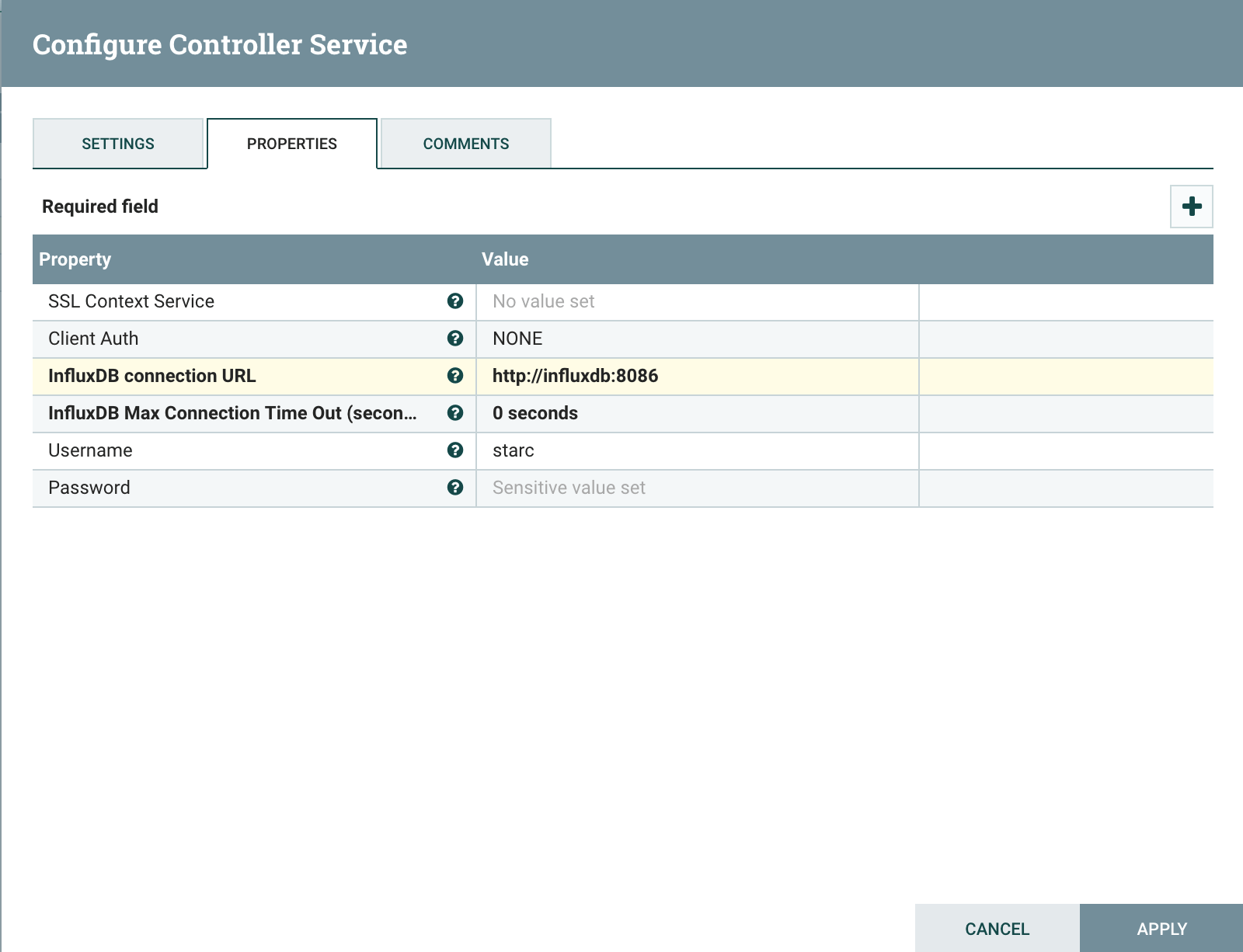
When finished, click apply and enable the StandardInfluxDatabaseService controller.
Finally, going back to the properties tab of your PutInfluxDatabasesRecord processor, you can now set the specified properties to write the content of the Records into InfluxDB database.
Since our record does not contain a field with a Measurement property value, we will simply set it to an arbitrary name (opc):
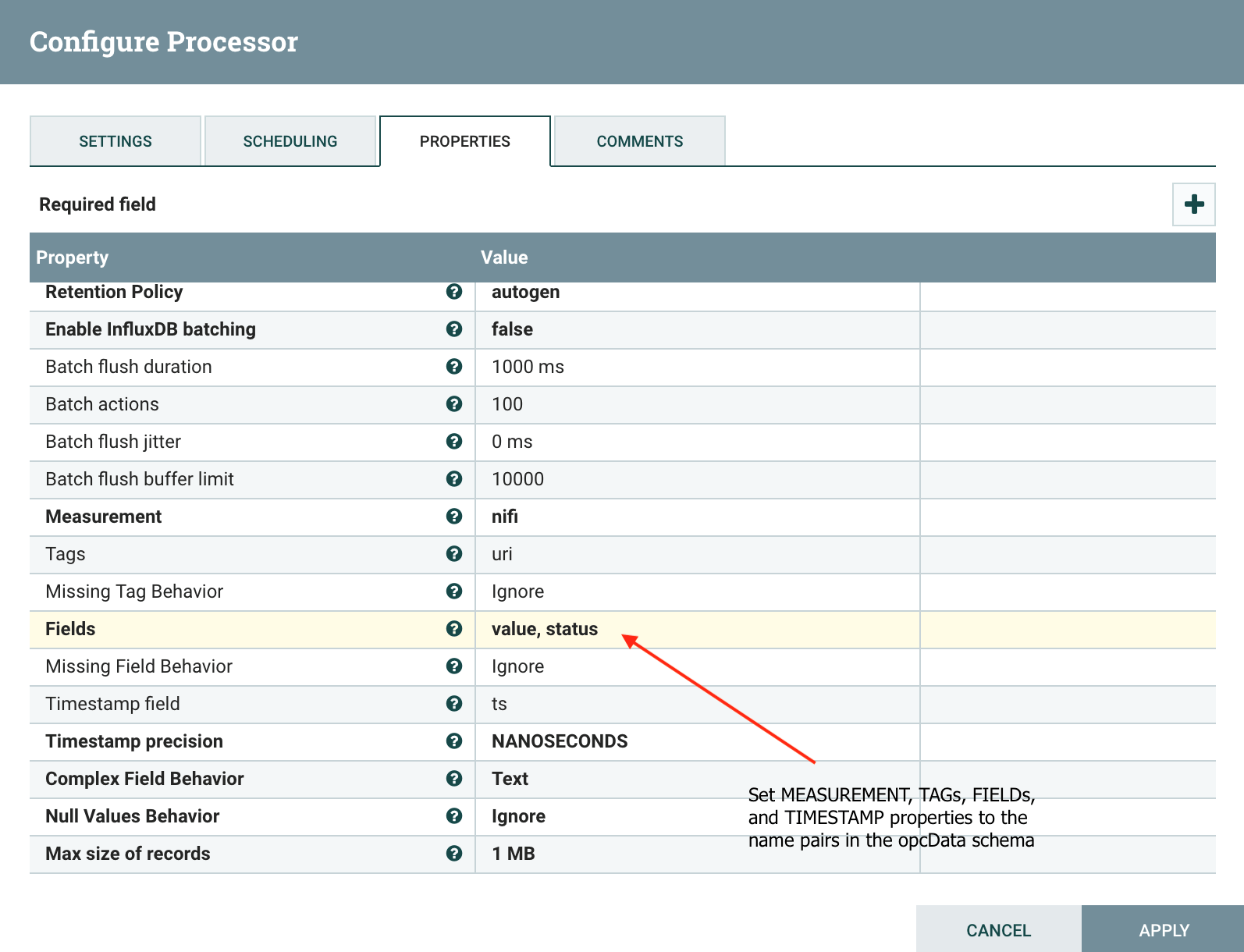
Using the name pairs from our schema, set the Tags, Fields, and Timestamp properties to names defined in the opcData schema.
Final processor flow and controller services
Finally, bringing all the processors and controllers enables a flow solution that intelligently collects and transmits more data to the data center over the WAN when a certain condition is met (high pump pressures are being recorded even when the downstream pumps are off). Once the controller services configuration is complete, it only takes about 5 more minutes to configure the flow.
Controller services:

AvroSchemaRegistry- Service for registering and accessing schemasCSVReader- Parses CSV-formatted data, returning each row in the file as a recordStandardInfluxDatabaseService- Service that provides connection to InfluxDBStandardOPCUAService- Fetches a response from an OPC UA server
Process flow:
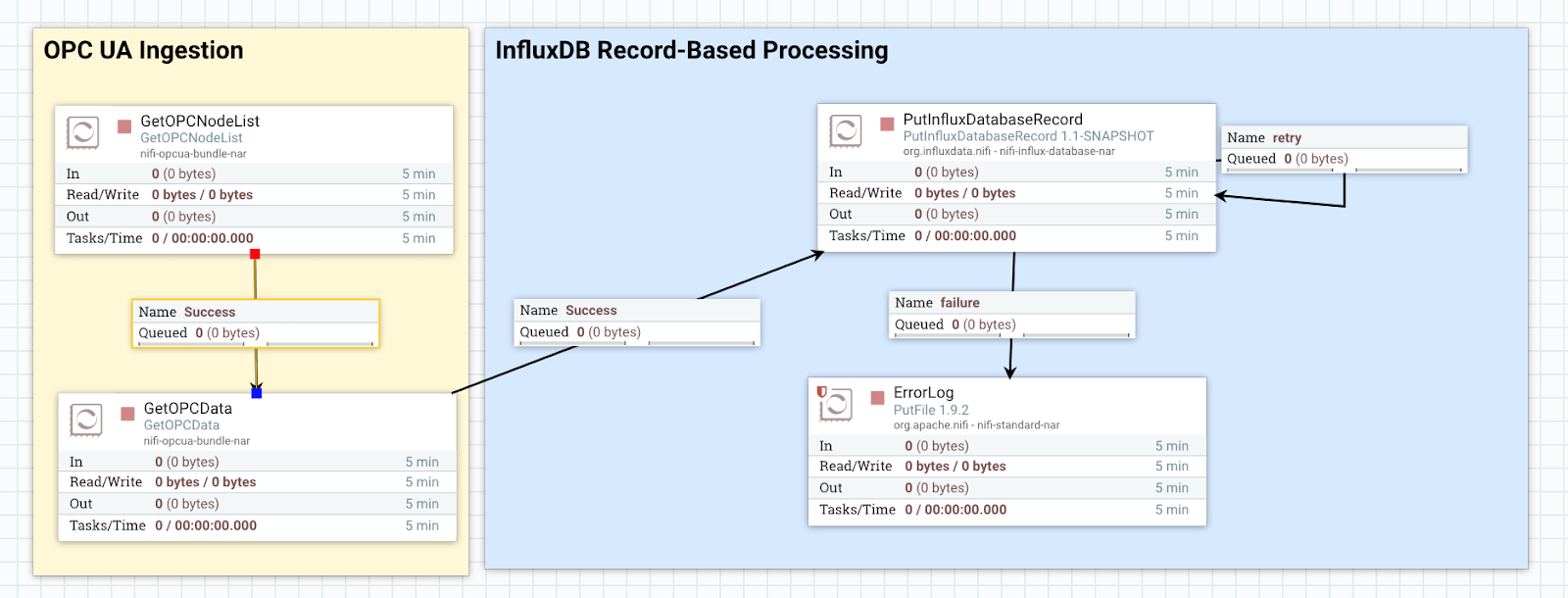
GetOPCNodeList- Access to tags currently in the OPC UA serveGetOPCData- Fetches values from the OPC UA serverPutInfluxDatabaseRecord- Write NiFi Record structured into InfluxDB
Now all that’s left is to start your NiFi flow.
Note: Consider the above flow sample for test only. In a production setting, you ideally would have more error handling processors and redirect queues.
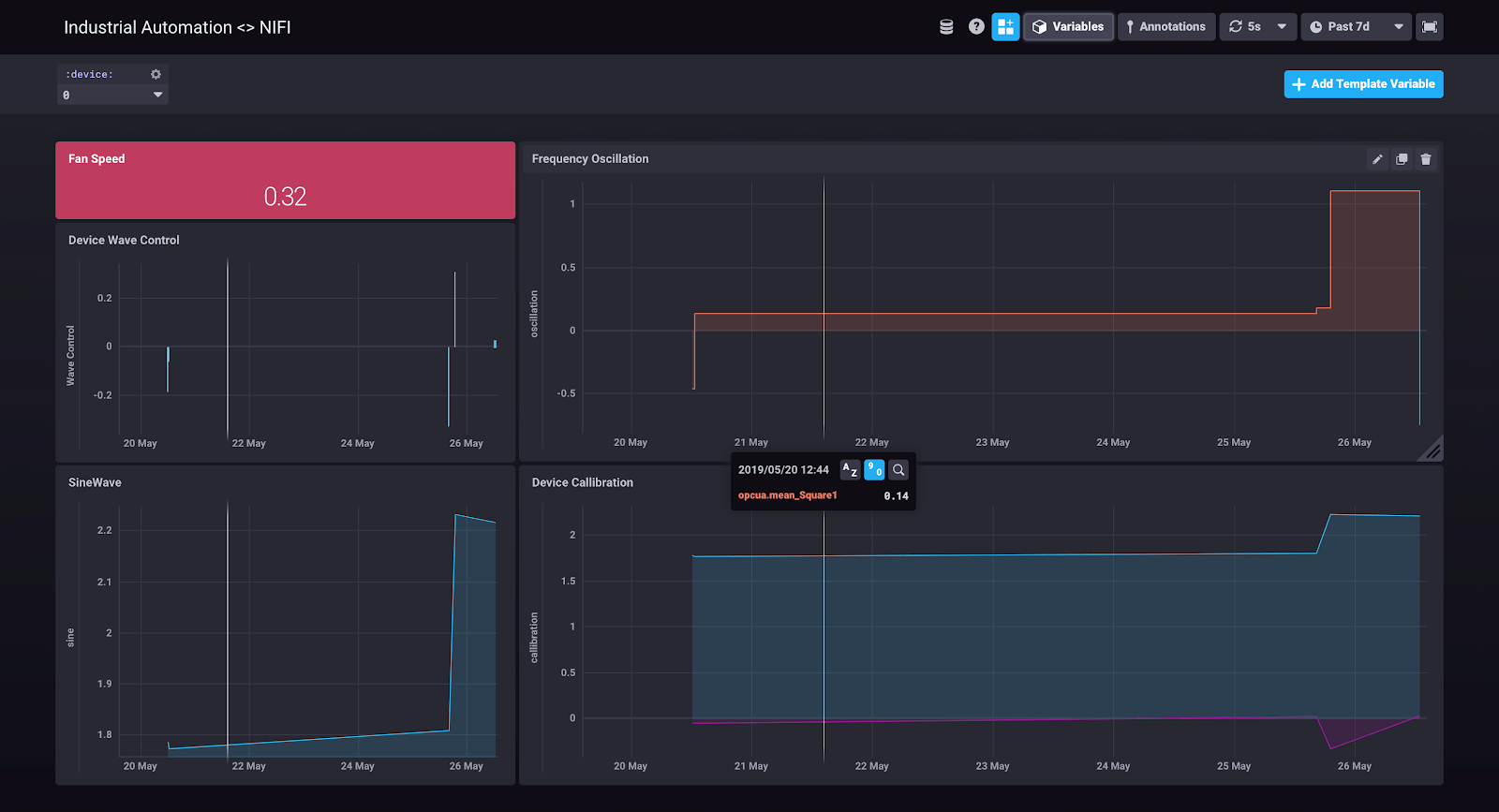
Explore your data in Chronograf
You can now easily jump into Chronograf and start creating dashboards on your sensor data. Click on Data Explorer, and find other sensor fields in the nifi.autogen database. Once you start seeing data, you can begin creating some dashboards.Note: Consider the above flow sample for test only. In a production setting, you ideally would have more error handling processors and redirect queues.
Conclusion
If you’re limited by the analytics capabilities of your traditional systems and are looking to leverage your OPC-based data in a more modern toolset, NiFi + InfluxDB make for a powerful combination that you can deploy quickly and securely.
Using this combination, administrators can easily and quickly integrate into enterprise-wide automation and business systems. System integrators can removing legacy barriers between traditionally proprietary factory floor devices and other manufacturing software.

