InfluxDB and Kafka: How Companies are Integrating the Two
By
Anais Dotis-Georgiou
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
As Kafka and time series databases gain popularity, it becomes increasingly valuable to understand how they are paired together to provide robust real-time data pipeline solutions. As the saying goes, the whole pipeline is greater than the sum of the Kafka and InfluxData parts.
Part One of this blog series includes:
- An introduction to Kafka
- Some basic Kafka concepts
- How companies integrate Kafka with InfluxDB to create tolerant, scalable, fast and simplified data streams
What is Kafka?
According to Wikipedia, “Apache Kafka is an open-source stream-processing software platform, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.” In other words, it allows you to build sophisticated data pipelines. Kafka is like three pieces of technology rolled into one:
- Message Queue – it reads and writes streams of data.
- Message Broker – it processes the messages and applies different logic to them to react to events in real time.
- Data Store – the decoupling of publishing and consuming messages means that Kafka stores those in-flight messages.
Now let’s talk about some of those buzzwords. According to Kafka, here’s what sets it apart:
Horizontally scalable
Shared Message Queues and Traditional Publish-Subscribe models precede Kafka’s. With Shared Message Queues, all of the messages fall into the same logical domain. This means that they all execute the same functionality – the processing isn’t scalable.
With Traditional Publish-Subscribe models, the messages are assigned to different topics which execute different functions. However, each message is published to each topic, and each subscriber must subscribe to each topic. As your network grows, the complexity of your stream increases exponentially. The resulting instability limits the degree to which Traditional Publish-Subscribe models can scale.
In other words, Kafka can scale processing and is multi-subscriber, making it truly scalable. To learn more about the differences between Shared Message Queues and Traditional Publish-Subscribe models, I highly recommend reading this article. Take a look at the documentation to learn more about how Kafka differs from its predecessors.
Fault-tolerant
This one is easy. Because Kafka is horizontally scalable and designed to run as a cluster, you won’t lose your messages or processing protocol if one node goes down.
Wicked fast
A short answer might attribute Kafka’s speed to it being written in Scala and Java, being open source, and contributed to by a wicked smart community. A better answer would touch upon 3 points:
- Kafka writes everything to disk instead of memory through Sequential I/O.
- Kafka avoids redundant data copy.
- Kafka batches messages.
The basics of Kafka
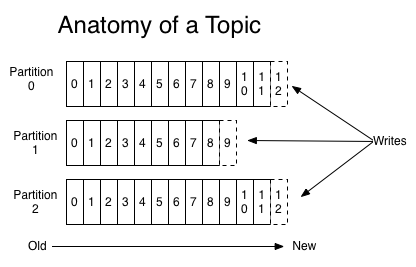
- Topics – categories for messages. They are multi-subscriber and can have multiple consumers. Each topic has a partitioned log. A Topic looks like this:
- Producer – publish data to the appropriate topics.
- Consumer – applications that subscribe to Topics. Consumer instances can be in separate processes or machines to ensure high-availability.
- Consumer Groups – contain 2 or more consumers instances. The messages are load balanced across consumer instances in a consumer Group
- Brokers – responsible for taking data from the producers and sending it to the consumers.
- Partition – an ordered, immutable, append-to log. Records are each assigned an offset value that identifies their position in the Partition. The partitions are distributed and replicated over a Kafka cluster. While each Topic Partition must fit on a server, they enable Topics to scale beyond a single server. The Broker with the partition with the highest offset is the leader. The rest of the brokers are followers. The leader handles the read and write requests for the Partitions. The following brokers replicate the leader. If the leader becomes unavailable, a follower is selected to take the failed Leader's position.
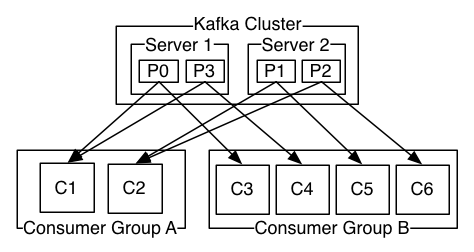
- Parallelism – Parallelism is the simultaneous execution of multiple processes. Each partition is consumed by exactly one consumer in a consumer group. However, consumers can consume records in parallel. If a consumer stops, Kafka can spread the partitions across the other consumers in the consumer group. In this way, partitions are a unit of parallelism.
- Ordering – Since each partition is read and consumed by exactly one consumer in a consumer Group, Kafka is able to guarantee ordering. This is opposed to tradition queues where multiple consumers read and consume from the same queue and the ordering of records can be lost. I recommend reading this blog to learn more about parallelism and ordering within Kafka.
- Processing – the Stream API enables real-time processing of data streams. With it you can perform aggregations or joins streams together.
How Hulu and Wayfair are using InfluxDB and Kafka together
Hulu reduced their tangled celtic knot stream to a stable, fast, and durable stream with Kafka and InfluxDB and solved the problems that come with Traditional Publish-Subscribe models. Hulu used Kafka and InfluxDB to scale to over 1M metrics per second. With this new design, they are prepared to handle any problematic InfluxDB cluster. In the event that one goes offline, Kafka redirects writes to another InfluxDB cluster until the cluster is back up, ensuring consistency. They are also able to disable huge portions of their infrastructure and route the workload to datacenter another easily and without impacting the user.

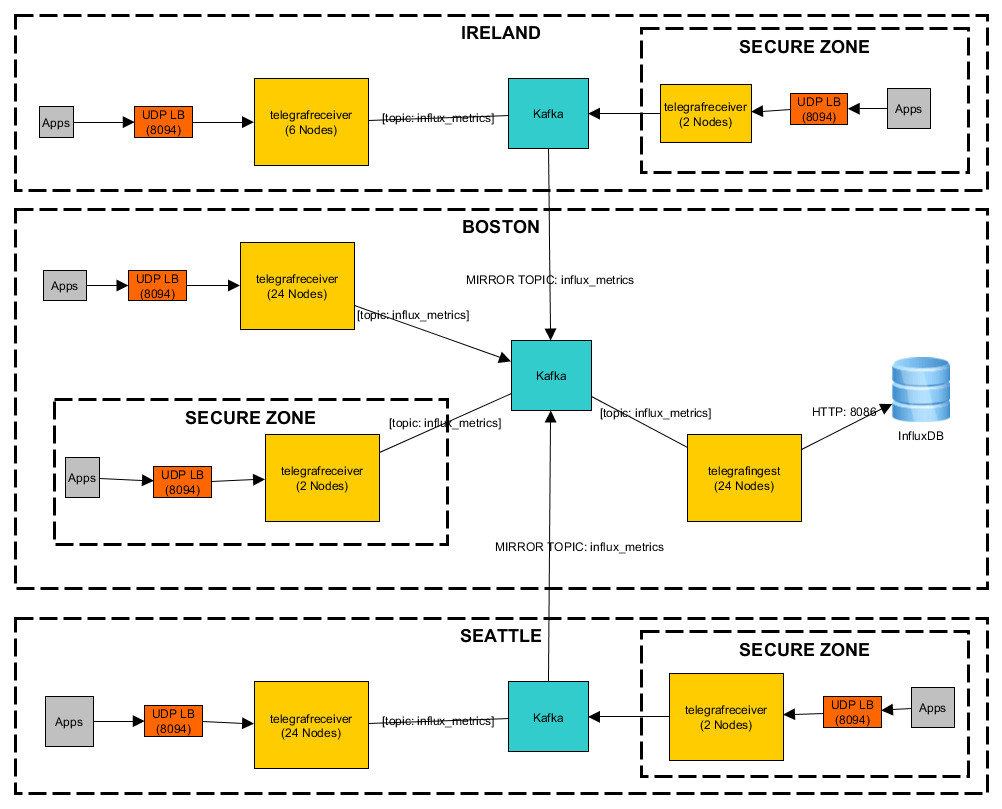
Wayfair uses Kafka as a Message Queue for application metrics. In their architecture, Kafka is sandwiched between Telegraf agents. An Output Kafka Telegraf agent pipes metrics from their application to Kafka and then the Kafka-Consumer Telegraf agent collects those metrics from Kafka and sends them to InfluxDB. This model enables Wayfair to connect to multiple data centers, inject processing hooks ad hoc, and gain multi-day tolerance against severe outages.
Learn more about Kafka and InfluxDB
Kafka enables companies to architect real-time, scalable and tolerant data pipelines. Hulu uses InfluxDB and Kafka to tackle their high-throughput metric ingestion requirements. If you’re new to Kafka and this blog inspired you to try it out, take a look at Deploying Confluent Platform (Kafka) OSS using Docker and this Kafka-Docker repo. If you have any questions, please post them on our community site or Slack channel.
